VTuber が歌った曲をまとめたい 後半(実装編)
VTuber が歌った曲をまとめたい 前半(検討編) の続きです。
前半(検討編) のおさらい
- VTuber のすべての動画から、過去どんな曲を歌っていたか列挙したい
- 複数案を検討し、「動画コメント欄の時間指定コメントを使う」案で進むことにした
ざっくりイメージ
「チャンネル URL から曲目データベースができるまで」のざっくりイメージがこちらです。
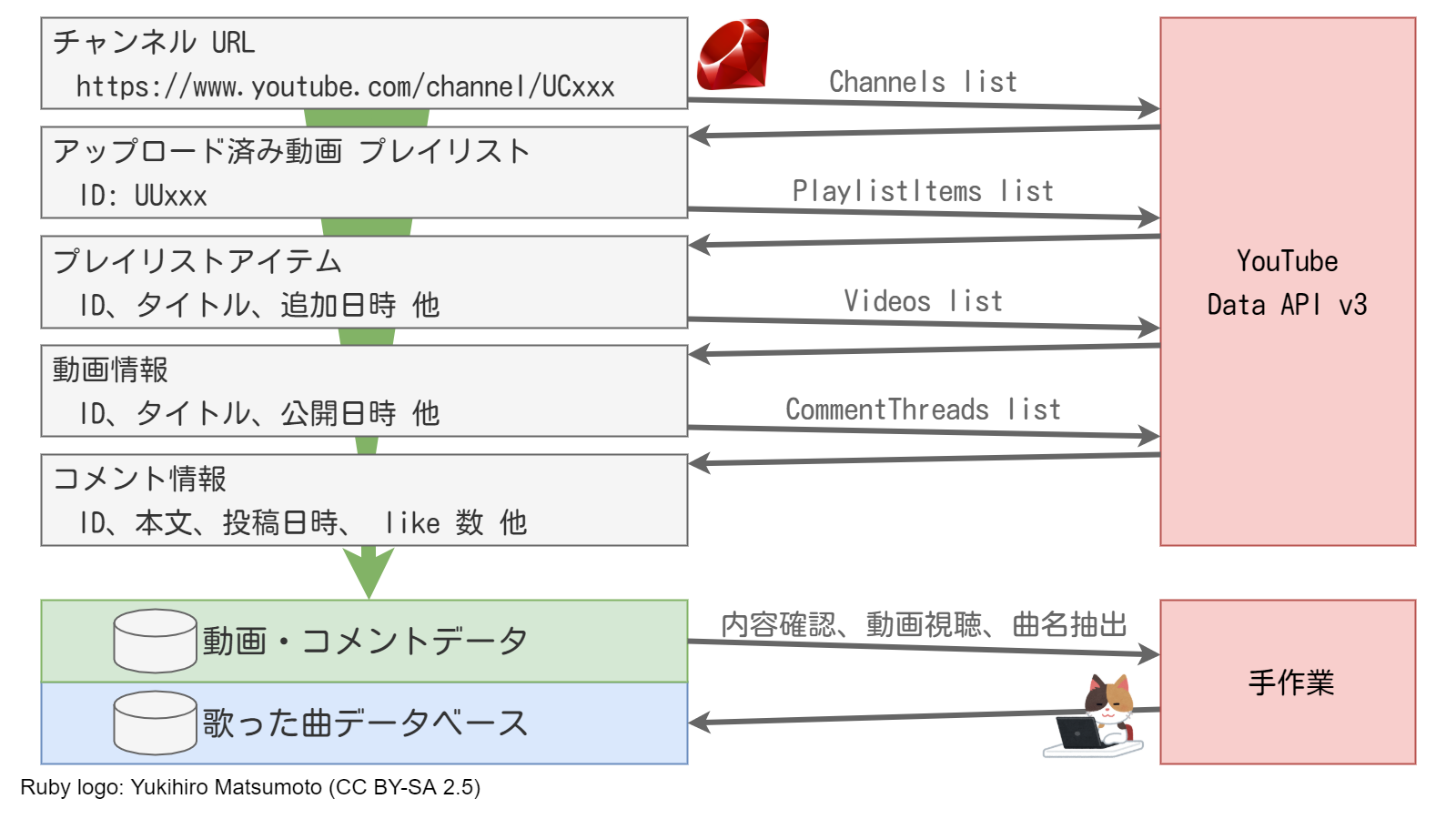
YouTube Data API v3 をフル活用し、 YouTube チャンネルを指定するだけで動画・コメントデータが抽出できるようにします。
ただし、「時間指定コメント」には曲以外のコメントも含まれるため、 データベース化するまでに手作業を挟みます。
データ抽出 (Ruby)
YouTube Data API Reference を参照してゴリゴリ書くだけです。書いたコードは GitHub にあります。
meliuta/utils/youtube-data-api-v3 at main · typewriter/meliuta · GitHub
以下は注意点です。
API クォータ
Quota usage | YouTube Data API Overview | Google Developers
- YouTube Data API は標準で 10,000 queries / day に制限されています。
- 今回使用する API のクォータ消費量はすべて 1 query / request のようです。日本語版ドキュメントにはパーツごとに追加消費がある旨の記述がありますが、英語版にはありません。実際に触ってみても追加消費があるように感じられませんでした。
チャンネル URL → アップロード済み動画 プレイリスト
Channels: list | YouTube Data API | Google Developers
- チャンネル URL の表現方法は 3 種類あります。チャンネル ID (
/channel/UCxxx) 、ユーザ名 (/user/xxx) 、 カスタムチャンネル URL (/c/xxx) です。このうち、カスタムチャンネル URL は非対応ですが、後述する Videos: list API に任意の動画 ID を投げるとチャンネル ID が取得できます。 - 次のステップで用いるプレイリスト ID は、レスポンスに含まれる
contentDetails.relatedPlaylists.uploadsの値を使用します。

アップロード済み動画 プレイリスト → プレイリストアイテム
PlaylistItems: list | YouTube Data API | Google Developers
- 50 を超える動画は 1 回では取得できません。レスポンスの
nextPageTokenがなくなるまで繰り返し取得する必要があります。 - レスポンスに含まれる
snippet.publishedAtはプレイリストへの追加日時であり、動画の公開日時とは異なります。 - 次のステップで用いる動画 ID は、レスポンスに含まれる
contentDetails.videoIdの値を使用します。
プレイリストアイテム → 動画情報
Videos: list | YouTube Data API | Google Developers
- レスポンスのサムネイル (
snippet.thumbnails.(key)) のキーに注意します。日本語版はdefault,medium,highの 3 種類しかありませんが、英語版のドキュメントにはstandard,maxresも記述されており、こちらが正確です。大きい順にmaxres,standard,highmedium,defaultです。
動画情報 → コメント情報
CommentThreads: list | YouTube Data API | Google Developers
- リクエストパラメタの
orderをrelevanceにすると、 YouTube サイト上での「評価順 (Top comments)」と同じ順序になるようです。 - PlaylistItems: list と同様、 100 を超えるコメントは 1 回では取得できません。レスポンスの
nextPageTokenを利用して繰り返し取得します。 - 曲目を列挙したコメントは評価が高いケースも多いため、 API クォータを意識して途中で打ち切るのも手です。
コメント情報 → 時間指定コメントの抽出

- コメントの
snippet.textOriginalを正規表現/(d+:\d+:\d+|\d+:\d+)/に掛けるだけのシンプルな方法で抽出します。 - コメントは自由形式で、曲名が同一行にあったり次行にあったりします。あまり最適化をせず、時間指定コメントをとにかく抽出することに割り切っています。
データベース化(手作業)
抽出したデータからデータベースを作っていきます。これは完全に手作業です。
- 曲名っぽい時間指定コメントを取捨選択
- 動画を再生して確認
- 曲名・アーティストなどを検索・記録
今回は素敵な素敵な「Google スプレッドシート」を使用しました。だいたい 1,800 コメントから 100 曲ほどをデータベース化できました。

なお、動画の時間指定リンクは https://www.youtube.com/watch?v=sshoDk2CQVQ&t=14118 のように、 t=秒数 を指定するだけです。
Web サイト化 (TypeScript, React)
こちらもゴリゴリ書くだけです。書いたコードは GitHub にあります。
API サーバを立てたくなかったため、フロントエンドでがんばる方向にしました。 Web サーバに生成物をポン置きするだけです。
- データベースは tsv ファイル
- TypeScript + React
- tsv ファイルの取得・解析
- material-table を使った表(検索・ページング機能含む)
出来上がった Web サイトがこちらです。
メリうた🐝 - メリッサ・キンレンカさんのお歌非公式まとめサイト
まとめ
なお、開発にあたり レヴィ・エリファ アーカイブス から着想を得ました。この場を借りて御礼申し上げます。