2025 年を振り返る
以前、はじめて転職活動をした際に「過去をしっかり振り返っておくことが大事」と言われたことがある。これに従って振り返る(過去分:2024年、2023年、2022年、2021年、2020年)。
技術的なもの
書籍に頼った 1 年
知識や手段を再整理するために、書籍に頼ることの多い 1 年だった。
根底には、コーディングエージェントの台頭などで「今のやり方で本当にいいんだっけ?」という疑いや悩みがあったと思う。
技術的だがお気持ちが強いもの
結局、内部品質が大事では?
コードの品質を高く保っていた「にも関わらず」速いのではない。コードの品質を高く保っていた「からこそ」速いのだ。このことを理解したら、ソフトウェア開発に対する見方が変わった。
David Scott Bernstein, 吉羽 龍太郎 他 訳. レガシーコードからの脱却 ―ソフトウェアの寿命を延ばし価値を高める9つのプラクティス. オライリー・ジャパン, 2019.
昨年引用した箇所だが、今年も「結局これでは?」と感じた。
私が経験した狭い範囲に限った話だが、内部品質が高いと感じるコードベースだと、人間もコーディングエージェントもサクサク開発が進められた。逆もまた然りだった。
技術的でないもの
古い建物、旧石器時代
- 遺跡
- 古い建物
特に「地底の森ミュージアム」は感動した。湿地帯などの条件が重なって木の根や幹が腐らずに残っていたらしく、それが発掘当時の状態で展示されていた。 古い建物では、時代だけでなく地域の気候などからくる違いなどが見えてきて、また少し楽しみ方が増えたように感じた。
また、大阪の国立民族学博物館の特別展「舟と人類―アジア・オセアニアの海の暮らし」(既に終了)で、 そもそもいつどうやって海を渡ってきたんだい? という点にも興味が湧いてきた。こういう繋がり・広がりは面白い。

「好き」「楽しい」のエネルギーは強い
最近個人的に思うのは、「好き」とか「楽しい」のエネルギーは強いし尊いということ。
大阪・関西万博でも、友人・知人との会話でも、ガイドやスタッフの方との会話でも。 自分まで楽しくなってエネルギーが湧いてくる。
反面、内側から湧くことが少なくなってきたように感じている。取り戻したい。
2024 年を振り返る
以前、はじめて転職活動をした際に「過去をしっかり振り返っておくことが大事」と言われたことがある。これに従って振り返る(過去分:2023年、2022年、2021年、2020年)。
技術的なもの
続・性能改善
「やりすぎず、よい匙加減で」「問題が起きる前に、予防的に」改善するのは結構難しい。
昨年の振り返りでこう書いていたが、今年を振り返ると「概ねうまくいった」と思う。
主に取り組んだのは以下の 2 ケース。
- 事前にアクセス集中が予測できていて、それを乗り越えるための性能改善
- 利用者数やデータ量の増加にあわせて、予防的にスケーラビリティを高めるための性能改善
Zenn のスクラップに整理したいと言いつつ全然出来ていないので、来年には整理する。
P2P 地震情報
Windows 版のアップデートを 2 回と、 Web 版のリニューアルを行った。
- Windows 版: Beta3.5(Rev11) を公開しました - P2P地震情報 開発ログ
- Windows 版: Beta3.5(Rev12) を公開しました - P2P地震情報 開発ログ
- p2pquake/web-client: P2PQuake Web client
技術的だがお気持ちが強いもの
『コードの品質を高く保っていた「からこそ」速い』
コードの品質を高く保っていた「にも関わらず」速いのではない。コードの品質を高く保っていた「からこそ」速いのだ。このことを理解したら、ソフトウェア開発に対する見方が変わった。
David Scott Bernstein, 吉羽 龍太郎 他 訳. レガシーコードからの脱却 ―ソフトウェアの寿命を延ばし価値を高める9つのプラクティス. オライリー・ジャパン, 2019.
このフレーズを強く実感した 1 年だった。コードの品質を高めるために、いろんなことをやった。
- 作るモノの目的や理由、背景を知っておく。よりよい設計・実装に繋がる。
- フィードバックサイクルをとにかく短くする。問題に素早く気づき、小さなコストで修正できる。
- 必要なら躊躇なくリファクタリングする。必要な機能が小さなコード・低い複雑度で得られる。
まだまだあると思うけれど、パッと思いつくのはこのあたり。
技術的でないもの
「古い建物」と縄文時代
古い建物が残る地区や、縄文時代・弥生時代の遺跡をいくつか訪ねた。

- 古い建物・町並み
- 遺跡
古い建物・町並みは以前から訪ねていたが、縄文時代・弥生時代に興味を持ったきっかけは、こうだ。
- 古い建物で「この時代はまだ板戸で、畳じゃなくて板の間でした」と言われ、 "古い建物=畳、襖" のイメージだったので何も知らないことに気づかされる。
- 建築系の書籍を何冊か読み始めるが、どの書籍にも「竪穴住居を建てて定住したのが始まりで…」などとある。
- はじまりの「竪穴住居」が気になりだす。
何が起こるかわからない世界だ。でも楽しい。
今のうちにやるマインドの高まり
2023 年、猛暑で綺麗な紅葉がなかなか見られなかった。今後も見られる保証はない。
歳を重ねるにつれて行動力も落ちてくるだろうし、「行きたい」と思ったときに行ける保証もない。
「来年でもいいや…」と言ってられなくなってきた。そんなこんなで、徐々に「今できることは今やる」マインドが高まりつつある。
2023 年を振り返る
以前、はじめて転職活動をした際に「過去をしっかり振り返っておくことが大事」と言われたことがある。これに従って振り返る(過去分:2022年、2021年、2020年)。
技術的なもの
性能改善
気がつくと前職でも現職でも性能改善をやっている。広く浅くではあるけれど、「やりすぎず、よい匙加減で」「問題が起きる前に、予防的に」改善するのは結構難しい。
徐々に体系化できつつある感触もあり、 Zenn のスクラップに整理していこうと考えている(自己流 Web サービスの性能改善のすすめかた)。
P2P 地震情報
Windows 版はバージョンアップを 3 回、スマホ版は 2 回行った。
- 2023/08/10: Windows 版: Beta3.5(Rev10) を公開しました - P2P 地震情報 開発ログ
- 2023/05/13: Windows 版: Beta3.5(Rev09) を公開しました - P2P 地震情報 開発ログ
- 2023/01/29: Windows 版: Beta3.5(Rev08) を公開しました - P2P 地震情報 開発ログ
- 2023/10/04: モバイル(iOS/Android) 0.9.6 リリース - P2P 地震情報 開発ログ
- 2023/05/15: モバイル(iOS/Android) 0.9.5 リリース - P2P 地震情報 開発ログ
技術的だがお気持ちが強いもの
1 月に転職して約 1 年。
仕事: 答え合わせの 1 年、過去一番コードを書いた 1 年
今年の個人テーマは「答え合わせ」。これまで培ったスキルや価値観はどこまで活かせるのか、そもそも世の中で求められているものなのか。結論から言えば、「活かせるし、求められているし、まだまだのびしろがある」。
加えて、過去一番コードを書いた 1 年だったと思う。徐々にコーディング力が衰えていると認識していたため、技術スタックが大きく変わった状況にも関わらず「書けるじゃん」という安堵と嬉しさがあった。
仕事: 大いなる力には、大いなる責任が伴う
昨年はかなり悶々としていたが、転職して状況が変わった。いまのところすごくフィットしている。
- 小規模なチームになった
- 開発の裁量のほとんどを持つようになった
- めちゃくちゃコードを書くようになった
ただし、大いなる力には、大いなる責任が伴う。言ったことはそのまま通ってしまうので、一言でプロダクトの成長を左右しかねない。
- CI/CD をどこまで整えるか
- テストコードをどのような基準でどこまで書くか(フロントエンドのテストを書き始めました)
- 数ある設計案のなかで、どれを選ぶか
- いまリファクタリングすべきか、そうでないか
プロダクトの現状や今後を見つつ、短期的・中期的・長期的それぞれの目線で考えつつ、最適な手を考えて打っている。
技術的でないもの
重要伝統的建造物群保存地区
「日本の町並み 250」という本で「(重要)伝統的建造物群保存地区」の存在を知り、町並み巡りが捗った。
いわむら城下町(岐阜県恵那市)・日本大正村(岐阜県恵那市)
— たいぷらいた〜 (@no_clock) 2023年7月28日
明知鉄道に乗って行きましたが、車窓から見える美しい田園風景もまた素敵でした。 pic.twitter.com/ItMw8G225B
中山道 醒井宿・居醒の清水(滋賀県米原市)・妻籠宿(長野県南木曽町)・奈良井宿(長野県塩尻市)
— たいぷらいた〜 (@no_clock) 2023年7月28日
妻籠宿と奈良井宿はどこを撮っても背景に山並みがあり、「木曽路はすべて山の中」を実感します。 pic.twitter.com/A1wjRxn3Ta
ワーケーション
千葉で数日、盛岡では 1 週間過ごした。いい気分転換になるし、刺激にもなった。
リモートワーク(千葉)で食べたもの pic.twitter.com/KfZq9KLKQe
— たいぷらいた〜 (@no_clock) 2023年3月11日
— たいぷらいた〜 (@no_clock) 2023年9月21日
おわり。
品質と工数をトレードオフにしない
ソフトウェアの外部品質を上げたい局面はいろんなところで発生する。不具合が発生した、障害が発生した、利用者が増えた… などなど。
このとき私がポリシーにしているのは、品質と工数をトレードオフにしない、ということだ。
品質が上がるが、工数も増えるケース
例えば以下のような対策は、品質が上がる一方で工数も増えてしまう。
- デプロイ前にチェックする手順を増やす
- プルリクエストの承認(レビュアー)を 1 人から 2 人以上に増やす
- 長時間の設計ミーティングに全員参加する
私はよく「開発プロセスが重たくなる」と表現している。
品質は上がるが、工数は変わらないケース
以下のような対策はどうだろうか。
導入工数はかかるが、日々プロセスを回していく工数はほとんど変わらない。開発プロセスが重たくならずに、品質が上がる。
私が好きな対策だ。選択肢が限られていたり、導入工数がかかったりと難しい面もあるが、だからこそ取り組む価値もあると考えている。
怠惰であれ
表に整理するとこんな感じだろうか。
| 品質\工数 | 増える | 変わらない | 減る |
|---|---|---|---|
| 上がる | それはそう | 💮 よい | 💮 素晴らしい |
| 変わらない | よくない | 今まで通り | 💮 よい |
| 下がる | よくない | よくない | それはそう |
もっと極端に言えば、「仕組みや自動化でなんとかなることを、わざわざ人の手でやりたくない」。そんな感じ。
2022 年を振り返る
以前、はじめて転職活動をした際に「過去をしっかり振り返っておくことが大事」と言われたことがある。これに従って、 2020 年、 2021 年と振り返っていたので、 2022 年も振り返る。
技術的なもの
新しいことにも手を出しつつ、 15 年以上続く P2P 地震情報の改善も継続して行った。
ISUCON 初参加(予選敗退)
ISUCON 初参加して 318 位と惨敗(ぎょうざとおこのみやき)。全然だったけど、スコアをちょっとでも上げることができて良かった(はず)
— たいぷらいた〜 (@no_clock) 2022年7月24日
ISUCON12 オンライン予選 全てのチームのスコア(参考値) : ISUCON公式Bloghttps://t.co/tIKBgZf1sv pic.twitter.com/lLy1hD1Y48
Rust で DNS フルリゾルバ実装
RFC 1035 を読みつつ Rust で DNS フルサービスリゾルバ実装。雑に動く感じにはなった pic.twitter.com/w2ZLrqH886
— たいぷらいた〜 (@no_clock) 2022年6月30日
P2P 地震情報
運用負荷軽減とパフォーマンス改善が中心。機能的には、緊急地震速報(警報)への対応が最も大きかった。
- www.p2pquake.net のサービスをぜんぶ Docker でコンテナ化した(計 35 コンテナ)
- パフォーマンス改善(配信遅延の短縮): 無事に 100 ms 以下になりました。やったぜ
- モバイル(iOS/Android) 0.9.4 リリース: 緊急地震速報(警報)に対応
- Windows 版: Beta3.5(Rev05) を公開しました
技術的でないもの
紅葉、雪見旅
東北~近畿地方を巡った。川瀬巴水「平泉金色堂」(絶筆)と同じ、雪がしんしんと降る中尊寺 金色堂は本当に良かった。

アプリの MAU を増やす
あるきっかけで、 P2P 地震情報の MAU を増やす工夫をいくつかやった。因果関係があるか分からないが、微増はしている。

技術的だがお気持ちが強いもの
より適したソフトウェアアーキテクチャを探る
ずっと KKD (勘と経験と度胸)に頼っていたが、仕事ではもうちょっと真面目にやりたくて試行錯誤した。効果があったなと感じているのは 2 つ。
1 つは、 Design It! の第 II 部 5 章「アーキテクチャ上重要な要求を掘り下げる」にある「アーキテクチャ上重要な要求 (Architecturally Significant Requirement: ASR)」の 4 分類。
- 制約
- 品質特性
- 影響を与える機能要求
- その他の影響を及ぼすもの
Michael Keeling; 島田 浩二. Design It! プログラマーのためのアーキテクティング入門 (Kindle の位置 No.1524-1526). 株式会社オライリー・ジャパン.
もう 1 つは、 Clean Architecture 第 15 章「アーキテクチャとは?」にあるこの一文。
ソフトウェアをソフトに保つには、できるだけ長い期間、できるだけ多く選択肢を残すことである。では、「残すべき選択肢」とは何だろうか? それは、重要ではない詳細である。
(略)
また、決定を遅延できれば、その分だけ適切に作るための情報が数多く手に入る。Robert C. Martin; 角 征典; 高木 正弘. Clean Architecture 達人に学ぶソフトウェアの構造と設計 (アスキードワンゴ) (Kindle の位置 No.2263-2265, No.2285-2286). 株式会社ドワンゴ. Kindle 版.
詳細はそれぞれ書籍を参照されたい。
この実践は、他人に説明しやすいというメリットもあった。一方、選択肢をどれだけ出せるかについては KKD (勘と経験と度胸)でやってしまっている。 2023 年の課題になるだろうか。
技術へのリスペクト
技術へのリスペクトがなくてもプロダクトやビジネスは成功するかもしれない。ただ、選択肢があるなら、技術へのリスペクトがある組織にいたい。ここ 1 年というより 2 年くらい感じていたことだった。
「 OOP の一番大事な要素ってなんだと思います?」とか「このサービス今作るとしたらどういう技術スタックにします?」とか、そういうお題で無限に雑談したいですね
— たいぷらいた〜 (@no_clock) 2021年5月24日
おわり。
デプロイ頻度を上げるための「下準備」
デプロイ頻度を上げた話ではなく、デプロイ頻度を上げるために必要なことを洗い出して実施したという話。
月 1 回のビッグバンリリース
所属チームは月 1 回のいわゆるビッグバンリリースで、まあ大変な状況だった。
- デプロイ作業は 2 時間超
- 500 ファイル以上の変更
- 「今月のリリースに間に合わせたい」ための行動が起きがち
Four Keys の話もあるし、列挙したチームの状況を鑑みても、デプロイ頻度を上げる価値はあると考えた。
いきなり毎日デプロイできるか? いいえ。
じゃあ月 1 回だったデプロイをいきなり毎日できるかというと、現実的ではない。今よりも大変になってしまうし、そもそも毎日デプロイするものもない。そんな状態で毎日デプロイしても価値は出ない。
まずは、デプロイ頻度を上げるための土台づくりが必要になってくる。 Four Keys はよくできているな… と感じる。
土台づくり
では、土台づくりで何をするか。ここの掘り下げは yigarashi さんの Four Keysがなぜ重要なのか - 開発チームのパフォーマンスを改善する方法について - yigarashiのブログ や 30分でわかるFour Keysの基礎と重要性 - Speaker Deck をめちゃくちゃ参考にした。その上で、チームの状況を見ながら以下の取り組みを行った。
プルリクエストを小さくする
デプロイ頻度を高めるには、デプロイする「モノ」を高頻度に生み出す必要がある。そのためには、プルリクエストを小さく分割し、高頻度にマージできるサイズになっていると良いはずだ。
チームでは、 Google Engineering Practices のコードレビューガイドラインを取り入れつつ、変更は最大でも 300 行以内という基準を設けた。
元々はコードレビューの遅さが嫌になって始めたものだが、巡り巡ってデプロイ頻度改善の下地にもなっている。
すばやくレビューする
チームではレビューを必須としているため、デプロイの高頻度化には素早いレビューも欠かせない。
これも Google Engineering Practices のガイドラインに従って 1 営業日以内のレビュー(またはレビュアー代打の提案)を行うようにした。また、別チームが開発したレビューリマインダー Bot を活用して、 1 日数回リマインドするようにした。
テストコードがない箇所は書く
例えばリファクタリングなら、 API の入出力が変化していないことを検証しておくと良い。シンプルに書くだけである。
一見、デプロイ頻度と無関係に思える。しかし、「高頻度にデプロイして大丈夫なんですか?」という不安に対する答えを用意しておくことは、意外と重要だと感じる。
カナリアデプロイを可能にする
万が一問題が発生したときの影響範囲を、可能な限り小さくしておく。
これもデプロイ頻度に直接作用するものではなく、不安を和らげる策の 1 つである。
素早いロールバックを可能にする
万が一問題が発生したときに、速やかに元に戻せるようにしておく。
これもやはり、高頻度なデプロイに対する不安を緩和するためのものである。
デプロイ作業を軽くする
これはデプロイ頻度に作用する。単純作業は自動化してしまえば良い。
ただ、チームには自動化までの道のりが長いプロセスもあった。具体的には、 QA (品質保証)と、受託開発でいう「受け入れテスト」相当のプロセス。
これについては、リファクタリングに限り、プロセスを思い切って省略することにした。
本来省略すべきものではないが、「事前に議論しても、リスクを取る選択はしづらいのでは」「一度やってみたデータがあるほうが、議論しやすいのでは」と考えた結果である。
試せる土台は整った
ここまでで、試しにデプロイ頻度を上げても良いと感じる程度には、土台は整ったと思う。
ひとり毎日デプロイ
単独で行っているリファクタリングのプロジェクトだけ、短期間毎日デプロイを試した。
思った以上に何も起こらなかった。
一度だけ不具合を起こしたが、原因を深掘りすると、従来のビッグバンリリースでも起きうる内容。カナリアリリースや素早いロールバックがプラスに働きそうだ。
あとはチーム次第
今後チームとしてデプロイ頻度が上がるかは、チーム次第。諸々の事情で遠巻きから見守ることになったので、本当にチーム次第である。
仮にデプロイ頻度が変わらなくても、それぞれの土台づくりが全く無駄になるわけではない。より高品質で、より安全なデプロイの一助になっているはずだ。
参考資料
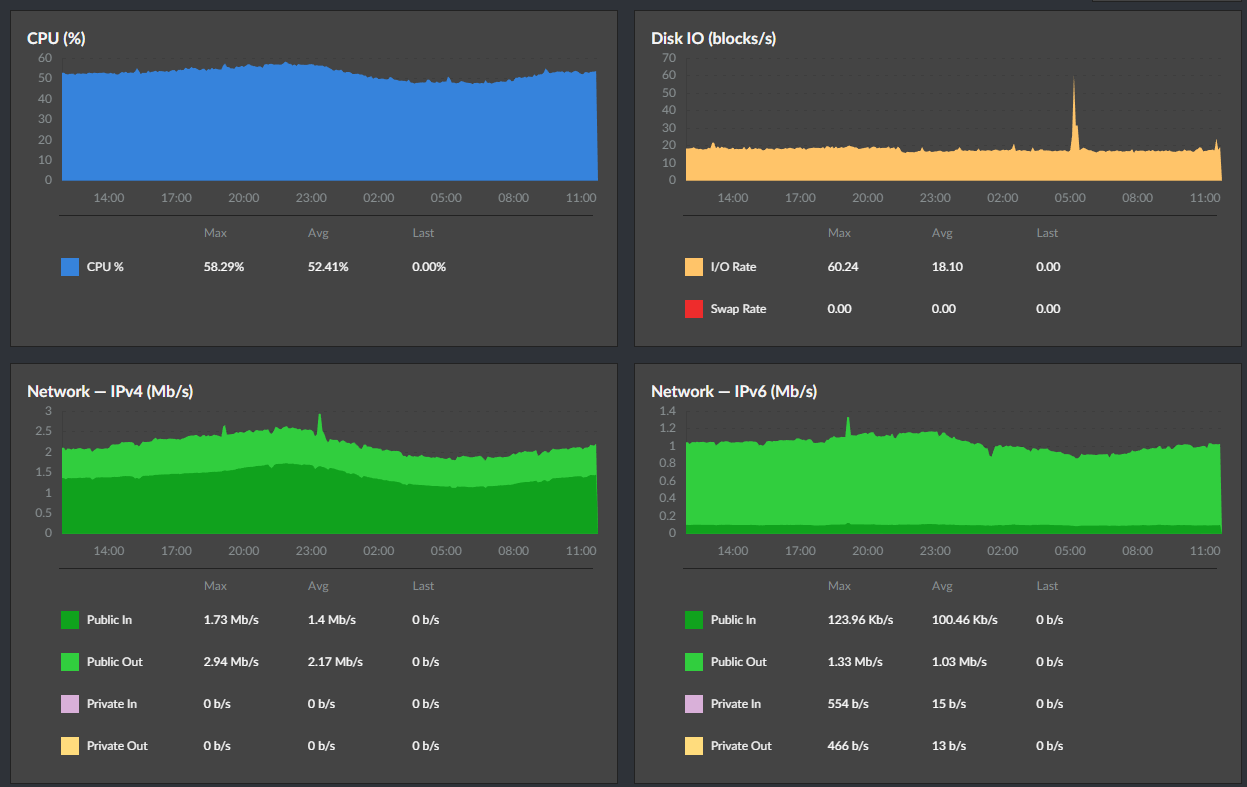
毎日 1000 万リクエストを捌く 1 台の API サーバー
P2P地震情報の API サーバー (api.p2pquake.net) は、毎日 1000 万リクエスト以上を捌いている。ピーク時は毎秒 300 リクエストを超える。
VPS 1 台でここまで到達するのにそこそこ試行錯誤した。結果として意外性はなくやることやっただけという感じではあるのだが、アーキテクチャーや設定値を整理して記事にしておく。
前提となる構成、及び状況
- Linode Dedicated 4GB プラン x 1 台
- CPU:
AMD EPYC 7601 32-Core Processor2 コア (専有)
- CPU:
- 公開 API は GET (読み取り) のみ

DB: MongoDB Capped Collections
DB はドキュメント指向データベースである MongoDB を使用していて、 API のレスポンスほぼそのままの形でデータを格納している。 2015 年頃から運用中(それ以前は CSV ファイルベース)。
> db.whole.find({ code: 551 }).sort({ $natural: -1 }).limit(1) { "_id" : ObjectId("63244a1551d38bb17b2e7c91"), "issue" : { "time" : "2022/09/16 19:04:04", "type" : "DetailScale", "correct" : "None", "source" : "気象庁" }, "timestamp" : { "convert" : "2022/09/16 19:04:05.177", "register" : "2022/09/16 19:04:05.204" }, "user_agent" : "jmaxml-seis-parser-go, relay, register-api", "ver" : "20220813", "earthquake" : { "foreignTsunami" : "Unknown", "time" : "2022/09/16 19:00:00", "hypocenter" : { "name" : "東京湾", "latitude" : 35.5, "longitude" : 140, "depth" : 20, "magnitude" : 2.5 }, "maxScale" : 10, "domesticTsunami" : "None" }, "points" : [ { "pref" : "千葉県", "addr" : "市原市姉崎", "scale" : 10, "isArea" : false } ], "code" : 551, "time" : "2022/09/16 19:04:05.204" }
最大の特徴は Capped Collections を使用していること。これはリングバッファー相当のもので、コレクションを一定サイズに保つことができ、古いドキュメントは自動的に消えていく(上書きされる)。直近の情報を提供できればよいP2P地震情報にぴったり合う。
ストレージエンジン WiredTiger のキャッシュは最小の 256 MB 。
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND systemd+ 1750 11.9 9.1 2210568 366816 ? Ssl Jul09 10836:08 mongod --wiredTigerCacheSizeGB=0.25 --auth --bind_ip_all
速度
速い。
P2P地震情報では 32 MB の小さな Capped Collection で運用していて、直近 10 件の地震情報を探す時間は 1 ms くらい。
> db.whole.stats() { "ns" : "p2pquake.whole", "size" : 33553274, "count" : 12057, "avgObjSize" : 2782, "storageSize" : 8462336, "freeStorageSize" : 2072576, "capped" : true (略) } > db.whole.find({ code: 551 }).sort({ $natural: -1 }).limit(10).explain("executionStats")["executionStats"]["executionTimeMillis"] 1 > db.whole.find({ code: 551 }).sort({ $natural: -1 }).limit(10).explain("executionStats")["executionStats"]["executionTimeMillis"] 0
Tailable Cursors
Capped Collections を使うメリットはもう 1 つあって、それが Tailable Cursors 。これは tail -f 相当で、簡易的な Pub/Sub として使える。
プッシュ通知、 WebSocket API 配信などで活用している。厳密には計測していないが、レイテンシは 1 ms あるかないか程度。
アプリケーションサーバー: Go
もともと Ruby + Sinatra だったが、新しい API については Go + Gin で作っている。古い API も徐々に Go + Gin に移行したい。
[GIN] 2022/09/10 - 08:42:13 | 200 | 2.064529ms | xx.xxx.xxx.xxx | GET "/v2/history?codes=551" [GIN] 2022/09/10 - 08:42:14 | 200 | 19.144558ms | xx.xxx.xxx.xxx | GET "/v2/history?codes=551&limit=40"
Web サーバー: Nginx
アプリケーションサーバーへのリクエストをとにかく減らす ため、キャッシュ設定を諸々行っている。
- proxy_cache_lock: キャッシュ期限切れでアプリケーションサーバーへのリクエストが必要になったときに、同じ URI のリクエストに対し 1 個だけリバースプロキシして他はそれを待つという挙動となる。
- proxy_cache_use_stale: アプリケーションサーバーへのリクエストが失敗した場合、期限切れのキャッシュがあれば使う。

server ブロック抜粋:
proxy_cache_use_stale timeout updating http_500 http_502 http_503 http_504;
proxy_cache_lock on;
proxy_cache_lock_timeout 30s;
proxy_cache_valid 200 1s;
proxy_cache_valid 302 1h;
proxy_connect_timeout 5s;
proxy_next_upstream error timeout http_504 http_502;
location /v2/ {
limit_req zone=apiv2 burst=10;
proxy_cache cache;
proxy_pass http://127.0.0.1:10001;
}
location /v2/jma {
limit_req zone=apiv2jma burst=10;
proxy_cache cache;
proxy_cache_valid 200 10s;
proxy_pass http://127.0.0.1:10001;
}
Nginx に 142 requests/s 来ているが、 アプリケーションサーバーに到達しているのはわずか 6% の 8.13 requests/s である。

あとはファイルディスクリプタ数の上限や worker_connections を引き上げたり、 net.ipv4.tcp_tw_reuse を 1 にしたり、くらい。
課題
TLS の負荷(たぶん)
諸々の結果、いま最も CPU リソースを消費しているのは Nginx になっている。
HTTPS ではなく HTTP でベンチマークを流すとこんな負荷は掛からないので、 TLS の負荷だと推測している。
top - 11:40:50 up 63 days, 15:47, 1 user, load average: 0.42, 0.84, 1.05
Tasks: 247 total, 2 running, 245 sleeping, 0 stopped, 0 zombie
%Cpu(s): 15.2 us, 14.3 sy, 0.0 ni, 68.0 id, 0.0 wa, 0.0 hi, 2.5 si, 0.0 st
MiB Mem : 3931.3 total, 358.7 free, 2375.9 used, 1196.6 buff/cache
MiB Swap: 4608.0 total, 3882.1 free, 725.9 used. 1208.3 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1676684 systemd+ 20 0 163092 79328 32748 S 12.5 2.0 496:19.37 nginx: worker process
1750 systemd+ 20 0 2210568 379080 10656 S 8.2 9.4 10913:42 mongod --wiredTigerCacheSizeGB=0.25 --auth --bind_ip_all
2802253 root 20 0 749316 67716 9608 S 5.2 1.7 3185:14 /usr/bin/cadvisor -logtostderr --global_housekeeping_interval=5m0s --housekeeping_in+
524 root 20 0 2640424 151960 18512 S 3.8 3.8 3667:06 /usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock
2243005 root 20 0 721888 26240 14152 S 2.7 0.7 25:08.70 ./web-api-v2
2242527 root 20 0 721056 28592 14348 S 1.9 0.7 25:02.20 ./web-api-v2
今後負荷が問題になってきたら、 ECDSA 証明書を試すか、 Load Balancer に TLS を終端してもらうかで考えている。
数百万件残っていたHTTPのはてなブログを4年越しにすべてHTTPS化させた話 - Hatena Developer Blog
最後に
まだまだ IPv4 アクセスが多い。