AWS App Runner のオートスケールは GCP Cloud Run ほど滑らかではなさそう
- 方法
- 同時接続数 4 で観察
- 突然 20 同時接続して観察
- まとめ: App Runner のオートスケールは Cloud Run ほど滑らかではなさそう
- 補足: App Runner の裏側は Fargate タスク (2023/05/06 追記)
先日、 AWS から App Runner というサービスが発表された。すごく GCP の Cloud Run っぽい。
ただ、新規サービス作成に 5 分待たされてしまった。
東京リージョンで nginx サービス作成時間 3 回はかってみたけど
— たいぷらいた〜 (@no_clock) 2021年5月19日
- GCP Cloud Run: 25 秒、 12 秒、 8 秒
- AWS App Runner: 360 秒、 322 秒、 225 秒
だった。内部の作りが全然違うのかなという印象
これはスケーラビリティにも不安があるな… と思い、ざっくりオートスケールの様子を調べた。
方法
コンテナの必要数が、クライアントの同時接続数に比例して増えていくだろうという算段である。コードは Gist に掲載している。
GCP Cloud Run と AWS App Runner のスケーリングの様子をみる · GitHub
サービスの設定は以下の通り。
| 項目 | AWS App Runner | GCP Cloud Run |
|---|---|---|
| リージョン | ECR: ap-northeast-1 App Runner: ap-northeast-1 (アジアパシフィック (東京)) |
GCR: asia (アジア) Cloud Run: asia-northeast1 (東京) |
| vCPU | 1 | 1 |
| メモリ | 2 GB | 256 MiB *1 |
| 同時実行数 | 1 | 1 |
| 最大インスタンス数 | 25 | 25 |
| 最小インスタンス数 | 1 *2 | 0 |
同時接続数 4 で観察
同時接続数を 1 分毎に 1 ずつ増やし、 4 まで増やして観察した。
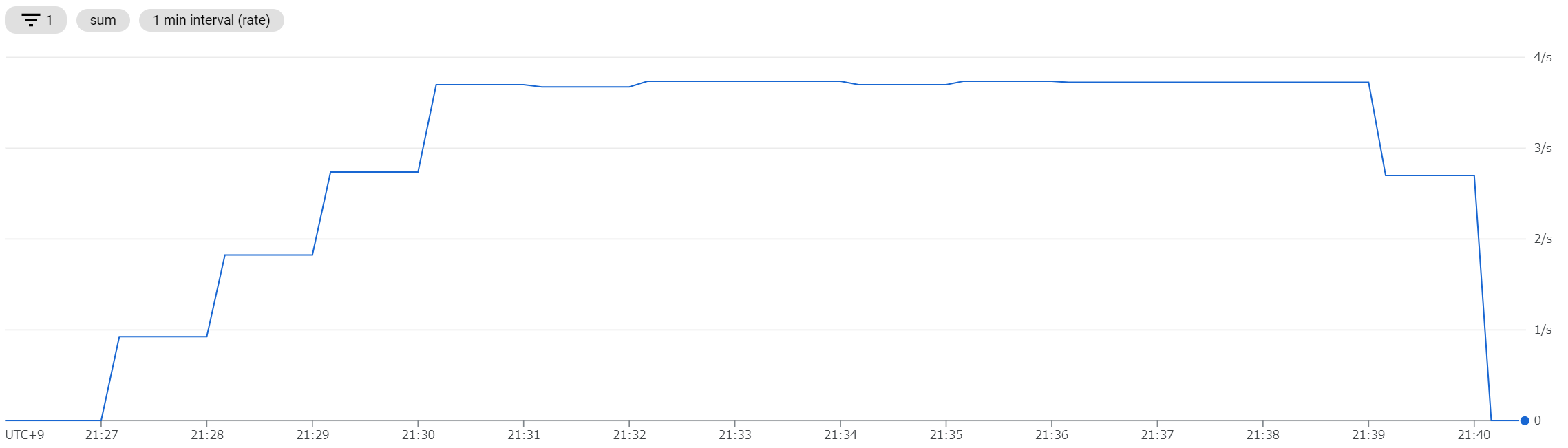
AWS App Runner: 20 インスタンスも起動する


同時接続数 4 のため、計算上は 4 インスタンスあれば十分。しかし、実際は 20 インスタンス起動している瞬間もある。
リクエスト数にきっちり追従していくというより、 余力を多めに確保しながらゆるやかに追従 しているように見える。
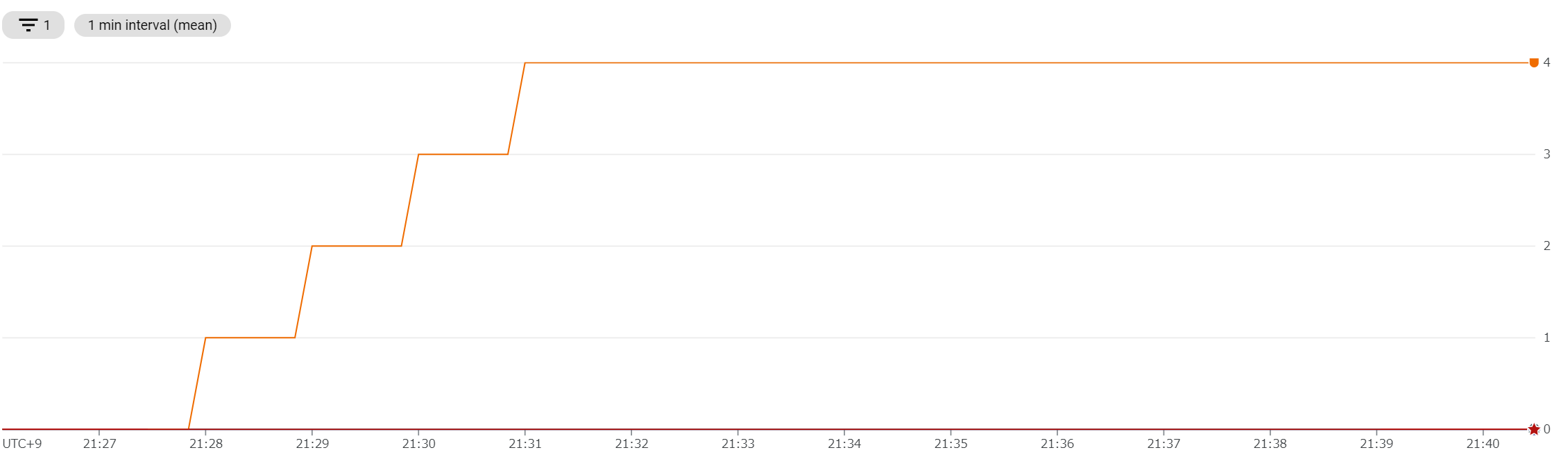
GCP Cloud Run: 4 インスタンスだけ起動する
上が リクエスト/秒 、下がインスタンス数である。こちらはリクエスト数にきっちり追従しているように見える。
突然 20 同時接続して観察
先ほどの結果から、 突然大量のリクエストを投げたら、 App Runner では捌けないのでは? という疑問が湧いたので観察。
httperf で一気に 20 接続、合計 1,000 リクエストを試みた。
$ httperf --ssl --server <hostname> --rate 20 --num-conn 20 --num-call 50
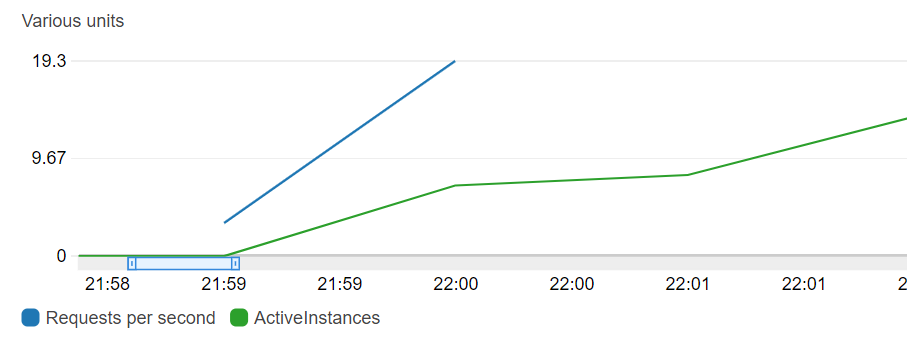
AWS App Runner: 過半数がエラーに
正常なレスポンスはわずか 209 個で 2 割ちょっと。過半数がエラーとなってしまった。
Total: connections 20 requests 762 replies 749 test-duration 28.729 s Connection rate: 0.7 conn/s (1436.4 ms/conn, <=20 concurrent connections) Connection time [ms]: min 552.5 avg 19523.6 max 28361.4 median 21879.5 stddev 6986.8 Connection time [ms]: connect 28.6 Connection length [replies/conn]: 37.450 Request rate: 26.5 req/s (37.7 ms/req) Request size [B]: 95.0 Reply rate [replies/s]: min 7.6 avg 29.7 max 56.0 stddev 17.6 (5 samples) Reply time [ms]: response 503.2 transfer 0.0 Reply size [B]: header 205.0 content 153.0 footer 0.0 (total 358.0) Reply status: 1xx=0 2xx=209 3xx=0 4xx=540 5xx=0 CPU time [s]: user 2.97 system 25.76 (user 10.3% system 89.7% total 100.0%) Net I/O: 11.6 KB/s (0.1*10^6 bps) Errors: total 13 client-timo 0 socket-timo 0 connrefused 0 connreset 13 Errors: fd-unavail 0 addrunavail 0 ftab-full 0 other 0
1 分毎のメトリクスであるが、同時接続数 20 に対し 7 インスタンスほどしか起動できておらず、インスタンスの増加が間に合っていないように見える。
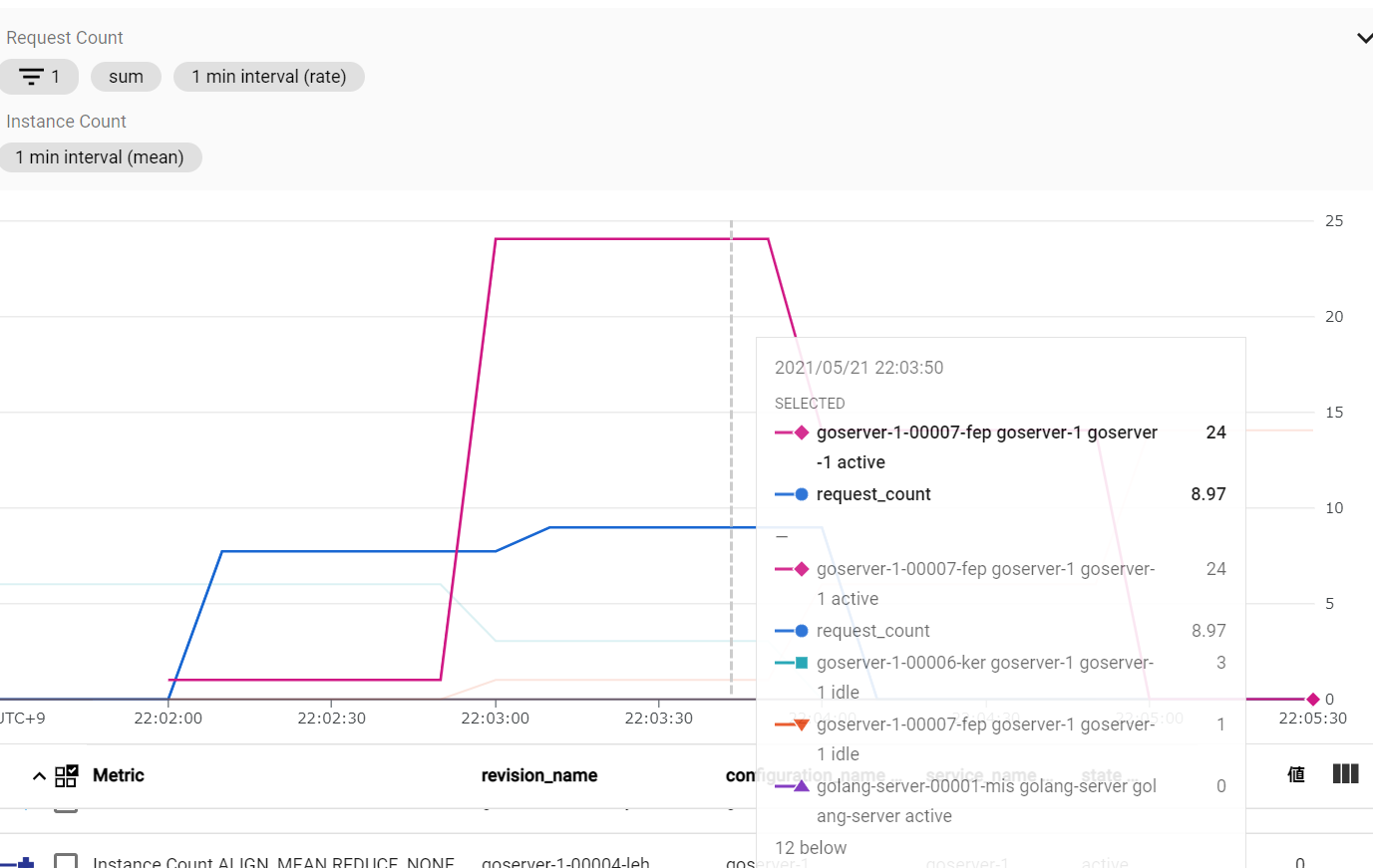
GCP Cloud Run: すべて正常応答
全リクエスト正常にレスポンスを受信した。
Total: connections 20 requests 1000 replies 1000 test-duration 52.689 s Connection rate: 0.4 conn/s (2634.5 ms/conn, <=20 concurrent connections) Connection time [ms]: min 51237.7 avg 51576.9 max 52157.5 median 51512.5 stddev 252.3 Connection time [ms]: connect 48.2 Connection length [replies/conn]: 50.000 Request rate: 19.0 req/s (52.7 ms/req) Request size [B]: 87.0 Reply rate [replies/s]: min 13.6 avg 19.0 max 20.0 stddev 1.9 (10 samples) Reply time [ms]: response 1030.6 transfer 0.0 Reply size [B]: header 378.0 content 278.0 footer 0.0 (total 656.0) Reply status: 1xx=0 2xx=1000 3xx=0 4xx=0 5xx=0 CPU time [s]: user 3.62 system 49.07 (user 6.9% system 93.1% total 100.0%) Net I/O: 13.8 KB/s (0.1*10^6 bps) Errors: total 0 client-timo 0 socket-timo 0 connrefused 0 connreset 0 Errors: fd-unavail 0 addrunavail 0 ftab-full 0 other 0
1 分毎のメトリクスにつき若干不正確だが、瞬時にインスタンス数が増加しているようだ。
まとめ: App Runner のオートスケールは Cloud Run ほど滑らかではなさそう
観察した範囲内では、 App Runner は Cloud Run と比べてオートスケールの動きは緩やか。急激なアクセスの増加に対しては、追従しきれない懸念がありそうな結果だった。
リリースされたばかりのサービスなので、今後に期待。
補足: App Runner の裏側は Fargate タスク (2023/05/06 追記)
AWS App Runner の VPC ネットワーキングに Dive Deep する | Amazon Web Services ブログ より図を引用すると、裏側では Fargate タスクが走っているようだ。

そもそも、 Fargate タスクは Lambda ほど素早く立ち上がらない。以前と比べて随分早くなったが、それでも Lambda や Cloud Run のように数百ミリ秒~数秒ではなく数十秒のオーダーである。あくまで個人的な考えだが、 App Runner に Lambda や Cloud Run 相当のスケーラビリティを求めるのは、そもそも間違っているということなのだろうと思う。