P2P 地震情報 Windows 版を「半分くらいクロスプラットフォームで」リニューアルしました
地震情報アプリ界隈 Advent Calendar 2021 14 日目の記事です。
P2P 地震情報 Windows 版を 10 年ぶりに更新しました。デザインは一新しましたが、目立った新機能はなく、未実装の箇所も残っています。
しかし、実は半分くらいがクロスプラットフォームになり、そのコードは Linux 上で動いていたりします。今回は、そのアーキテクチャをご紹介したいと思います。
P2P 地震情報とは
P2P 地震情報は、気象庁の地震情報・津波予報と、ユーザ同士の「揺れた!」という情報を P2P ネットワークで共有する無償のサービスです。

Windows 版のほか、 iOS 版、 Android 版、 Twitter @p2pquake 、さらに開発者向けに JSON / WebSocket API も提供しています。
旧 Windows 版の問題点
旧 Windows 版 (Beta3) は Visual Basic 6.0 で作っていました。運用を続けるうちに徐々に問題が生じてきました。
- 古すぎる。開発環境は 2008 年にサポート終了。実行は Windows 10 でも可能。
- マルチスレッドではない。 P2P 通信にはそもそも不向きである。
- API 提供にあたり、地震感知情報の収集のためだけに Windows 環境を常時運用する必要がある。
そこでリニューアルすることにしたわけです。
新 Windows 版のアーキテクチャ
新 Windows 版は、 Microsoft のソフトウェアフレームワーク .NET 5 で開発しています。もともと .NET Core と呼ばれていたもので、クロスプラットフォーム対応が特徴です。
開発・保守がしやすいよう 6 つのコンポーネントに分割していて、画面(ユーザインタフェース)を除く 5 つのコンポーネントがクロスプラットフォームに対応しています。

Web 版と地図は同じ
クロスプラットフォームであることの一例を見てみます。以下の画像は、 Linux サーバで動いている Web 版の地震情報地図と、新 Windows 版の地震情報地図を並べたものです。ほとんど同じです。 Linux でも Windows でも同じ地図生成のソースコードで動作しているためです。

アーキテクチャ詳解
ここからは少しだけアーキテクチャを詳しく見ていきます。
Client: サーバ通信、 P2P 通信、それらのコントローラ
コア部分にあたる Client は、 P2P 地震情報のピアとして動作するために、サーバ・ピア通信を担います。
デザインパターンの Mediator パターンと State パターンを組み合わせたようなクラス設計にしています。接続済の状態から切断するときは、ピアとの接続をすべて切断し、サーバに参加終了の通信をする… といった具合です。


地震情報などのデータを受信すると、下位クラスでイベントが発生し、上位へ運ばれ、最終的に最上位である MediatorContext クラスのイベントが発生します。画面にあたる WpfClient は、このイベントを処理して表示や通知をしています。
ソケットプログラミングは不安定で面倒なものです。接続済みかチェックしてデータを送信しても、送信する瞬間には切断されていることも珍しくありません。悲しいことに、ソースコードには try-catch が溢れています。

Map: ImageSharp によるクロスプラットフォーム描画
Map は地図生成を担います。といっても、地図生成には画像処理以外の要素も絡んでいます。
- 地図: 日本部分は地理院タイルを使用 (CC BY 4.0) 、それ以外は GSHHG のデータを用いて GMT で生成 (LGPL v3)
- 震度観測点: 気象庁 | 震度観測点 の情報を加工
- 震度速報地域の塗りつぶし: 気象庁 地震情報の GeoJSON データに基づき塗りつぶし範囲を決定(詳細: 地図を塗りつぶしたくて GeoJSON - Speaker Deck)
- 地震感知情報の塗りつぶし: 同上(気象庁の緊急地震速報や震度情報で用いる区域名と地震感知情報の地域名との対応は別途 Wiki ページに整理)
なお、クロスプラットフォームの描画ライブラリ SixLabors.ImageSharp を用いています。
WpfClient: WPF (Windows Presentation Foundation) による GUI
ユーザインタフェースを提供するのは WpfClient です。 ModernWpfUI を用いてモダンな見た目になっています。
モダンなのは見た目だけで、 WPF 自体はフレームワークとして「枯れた」部類に入っている気がします。 WinUI 3 や .NET MAUI がはるかにモダンです。ただ、ここで下手に躓いて開発が滞るのだけは避けたいという思惑がありました。
「 UI だけなら作り直しは簡単だから、まずは完成を」という気持ちで作りきったので、設計と呼べるものはあまりありません。 Program.cs は 400 行を超えて恥ずかしい感じになっています。ただ、クラスの依存方向が反転することが極力ないよう実装しています。
地震感知情報の地図生成については、 1 件ずつ生成していると受信ペースに追いつかないため、適宜生成を省略するように工夫しています。
選ばなかったアーキテクチャ
開発にあたっては、次のアーキテクチャも検討しましたが、最終的には選びませんでした。
- Electron: モダンなクロスプラットフォームとして最有力候補でしたが、既に安定稼働していた P2P 通信部分をきっちり移植できる自信がありませんでした。
- Electron.NET + Blazor (WebAssembly): P2P 通信部分がそのまま使えるものの、 ASP.NET Core が未知だったため躊躇しました。
- Client を gRPC サーバ化 + Flutter: Flutter デスクトップ対応があったので検討したものの、さすがに上記 2 案と比べても奇抜すぎて止めました。
クロスプラットフォーム対応の使いどころ
そんなわけで、半分ほどクロスプラットフォーム対応になっています。実は、 GUI 以外は既に Linux 環境で実際に運用しています。
- Map: Windows 版以外の地図画像を生成するために、 Linux サーバ上で実行
- Asn1PKCS: P2P 地震情報 サーバ (Linux 版) で利用
- Client, PKCSPeerCrypto: API 等で提供するための地震感知情報の収集に、 Linux サーバ上で実行
コンポーネント分割せずに失敗した過去
余談ですが、 Windows 版リニューアルは過去 2~3 度ほど試みていて、いずれも失敗していました。
野心的に新機能を盛り込みすぎたり、「一気に」作り直すやり方で進めていたりして、今振り返ると「そりゃ失敗しますよ」という感じがします。
今回は機能的にはかなり控えめにして、小さく分割して、「使えるところからどんどん動かしていく」という方法で進めました。少しずつでも「ちゃんと動いている」という安心感は、開発を前進させる力になりました。
YouTube コーディング配信
またまた余談ですが、開発の模様は一部 YouTube で配信していました。他人の開発風景ってなかなかまじまじと見る機会がないもので、ならば自分から、という感じでした。
1 ヶ月くらいで止めちゃいましたが、録画は続けていて 50 時間以上になっています。数分くらいに短くまとめて動画にしたいなと思っています(いつ完成するかはわからない)。
今後の課題
アーキテクチャや実装自体はかなり良くなりました。一方、機能としてはまだまだで、メモリ消費もかなり激しいです。
私も一利用者として使いつつ、完成度を高めていきたいと思います。
ソースコード
MIT ライセンスです。なんだかんだでそこそこのボリュームになりました(一部未コミットのコードを含みます)。
$ cloc . --include-ext=xaml,cs github.com/AlDanial/cloc v 1.82 T=68.71 s (5.7 files/s, 609.7 lines/s) ---------------------------------------------------------------- Language files blank comment code ---------------------------------------------------------------- C# 377 4986 4124 31773 XAML 18 41 16 952 ---------------------------------------------------------------- SUM: 395 5027 4140 32725 ----------------------------------------------------------------
テックリード 1 年半、試行錯誤の断片
1 年半くらいテックリードっぽいことをしている。具体的には、 higepon さんの以下記事にあるような役割を概ねやっているつもり。
振り返ってみて、試行錯誤の連続だったと思う。「こんな成果が出ました!(バン!)」って派手なものはなくて、様々なところで「こっちがいいですね」と走る方向を示し続けてきただけ、という気がする。
まだ浅い経験しかないけれど、自分なりの考えをいくつか整理してみた。月並みな内容ばかりだけど、将来見知らぬテックリードにちょっとでも役に立ったりすると嬉しい。
品質ではなくスコープを削る
アジャイル開発において、リリースを急ぐならスコープを削るべきで、品質を削るべきではないと常々思う。
品質を削ると痛い目に遭う。これは経験からくる感覚もあるし、t_wada さんの「質とスピード」やそこで引用されている書籍でもはっきり記されている。カジュアルなものだと、 Message Passing のトピック「締切のはなし」も近い。
スコープを削るために、「できない」と早く言う
スコープを削るのは早いほうがいい。途中で放棄するのはもったいないし精神的にもよろしくないからだ。
そのためには、プロダクトマネージャーに早く伝える必要がある。小さなタスクに分解してスプリントプランニングに組み込むよりずっと前に。ここでは 2 つのことを意識している。
- いつでもざっくり見積もりできる状態を保っておくこと。システムアーキテクチャは脳内にキャッシュし、次にやりそうな機能は予め把握しておく。「 3 ヶ月でどうですか?」と聞かれてパッと答えられないと、「じゃあ一旦 3 ヶ月で」となりがち。
- 直感で良いので数値で出すこと。「情報少ないので精度低いですが、(できる確率は 2 割くらい|その規模は 6 ヶ月くらい)だと思います」みたいに言う。これで概ねなんとかなっている(プロダクトマネージャーとの信頼関係にもよりそうだ)。
品質を削ったら、戻すのは極めて難しい
ここでいう品質は保守性などの「内部品質」である。これをうっかり削った後、ちゃんと戻った経験は今のところ 1 度もない。
2 つの側面があると思っている。
- 後からリファクタリング単体で行うのは難しいということ。 動作するきれいなコード: SeleniumConf Tokyo 2019 基調講演文字起こし+α - t-wadaのブログ にもあるけれど、『価値を生まないように見える』活動を理解してもらうのは難しかった。また、品質を削るほどの開発は大抵リリースでヘトヘトになっていて、リファクタリングに消極的だったりした(気持ちはよくわかる)。
- 割れ窓理論やコードの一貫性。「元の実装がこうだったので(今回だけ綺麗にしても…|一貫性を重視しました)」みたいな話である。ボーイスカウト・ルールを持ち出して「一緒にリファクタリングしちゃいませんか」と言っても、コードベースが大きすぎるとリファクタリングした本人へのメリットはかなり薄まってしまう。
つまり、リリースまでにできるだけ品質を上げておく
内部品質を削ると戻りにくいのであれば、削らないようにするしかない。
スコープを削るのはもちろんだけど、最近は「内部品質にこだわる雰囲気」を作るように努めている。
- コードレビューの改善。 Google Engineering Practices で 一石六鳥のコードレビュー - Speaker Deck に書いたが Google Engineering Practices を取り入れた。まだ 1 ヶ月半なので成功と言い切るには早いが、ざっくばらんなディスカッションや考えがコメントされている頻度がかなり増えたと感じる。いい傾向だと思う。
- リーダブルコードの輪読会兼実践会。リーダブルコードは、「わかっちゃいるけど実践が難しい」類の本だと思う。実際のプロダクトのコードをリファクタリングすることで、実践の仕方をみんなで学んでいる。
この 2 つを並行で進めていて、この相乗効果はかなり良い。コードレビューで「リーダブルコードの…」とか、輪読会で「この間のコードレビューを例にすると…」と相互に話題が挙がっている。
「危険な匂い」を伝える術が見つかっていない
これは悩み。 Code smell みたいな話。コードに限らず、将来障害が起きそうだなといった「危険な匂い」を感じ取ったときに、それを適切に伝える術が見つかっていない。
ハイコンテクスト文化だと「これ危ないですよね?」「あー危ないですね」で片付くもので、今まではそれに甘えてなんとかなっていた。でもそうでない文化圏が入ってくると、「これ危ないですよね?」「…?(具体的なリスクや取るべきアクションを共有してもらえませんか…?)」といったすれ違いになっている感じがする。
難しいと思っているのは、この「危険な匂い」の根拠が乏しい点。これまでの知識や経験を総合しているとして、それを紐解いて丁寧に説明できるほどには記憶が残っていない。そのため、筋道を立てて説明ができず、「例えばこういう(事例|アクション)があるかもしれません」という断片的な説明しか出来なかったり、「伝わってくれ…!」という願望しか表現できなかったりする。
書籍を読んでみている
この状況を緩和するために、まさに「紐解いて丁寧に説明」しているであろう書籍を読み直している。改めて読んでみると、 SRE 本とか Code Complete とか、「なぜそれが大事なのか」が結構書かれていたりする。やや遠い道のりではあるが、知識や経験の総合なのだとしたら仕方がない気もする。
ハイコンテクスト文化圏に引っ越すほうが早いかもしれない、と頭をよぎる瞬間は何度もある。どこまで試すかはまだわからない。
また断片が集まってきたら書くつもり。
.NET 5: System.Drawing.Common と ImageSharp 、 Windows と Linux でテキストレンダリングの差をみてみる
クロスプラットフォーム。プラットフォーム間の差異に悩まされる地獄だ。
ということで、 .NET 5 でのテキストレンダリングの差を調べてみた。フォントは等幅な Roboto Mono とプロポーショナルな Roboto を用いた。
- System.Drawing.Common 5.0.2
- SixLabors.ImageSharp 1.0.3 / SixLabors.ImageSharp.Drawing 1.0.0-beta11
- 処理時間
System.Drawing.Common 5.0.2
Windows の GDI+ API を使うライブラリ。ただし、 Unix 系でも Mono のオープンソース実装 libgdiplus を入れると動作する。ソースコードを拝見すると、 GdiplusNative.Unix.cs といったファイルがあって大変そうだ…
TextRenderingHint プロパティでレンダリングモードが指定できるので、すべて試した。
Roboto Mono



全く同じ結果は得られなかったが、 AntiAliasGridFit と ClearTypeGridFit はかなり近い。
Roboto



結構な差が出てしまった。
SixLabors.ImageSharp 1.0.3 / SixLabors.ImageSharp.Drawing 1.0.0-beta11
クロスプラットフォームライブラリ。 System.Drawing 名前空間のドキュメントにも「代替手段」として例示されている。
図形や文字を描画するための SixLabors.ImageSharp.Drawing はまだベータ版で、 Getting Started に API 変えるかもよと注意書きが入っている。
カーニング (TextOptions.ApplyKerning) とアンチエイリアス (GraphicsOptions.Antialias) の有無をそれぞれ変更して試した。
Roboto Mono



同じ結果が得られた。
Roboto



プロポーショナルフォントでも同じ結果が得られた。
処理時間
こうなると ImageSharp を使わない理由はないように見えるが、処理時間に大きな差がある (以下 10 回の平均値)。
| プラットフォーム | System.Drawing.Common | SixLabors.ImageSharp |
|---|---|---|
| Windows 10 20H2 | 27 ms | 419 ms |
| Ubuntu 20.04.1 LTS | 59 ms | 282 ms |
詳しく見てみると、 4 行あるテキストの 1 行目のレンダリングだけが遅い。フォントの読み込みだろうか。
| タイミング | 経過時間 (Windows 10 20H2) |
経過時間 (Ubuntu 20.04.1 LTS) |
|---|---|---|
| 新規画像生成 (640x480, 白塗りつぶし) |
38 ms | 43 ms |
| FontCollection, Font 作成 | 60 ms | 72 ms |
| 1 行目レンダリング | 365 ms | 228 ms |
| 2 行目レンダリング | 368 ms | 231 ms |
| 3 行目レンダリング | 372 ms | 234 ms |
| 4 行目レンダリング | 375 ms | 238 ms |
| PNG 画像出力 | 419 ms | 282 ms |
AWS App Runner のオートスケールは GCP Cloud Run ほど滑らかではなさそう
- 方法
- 同時接続数 4 で観察
- 突然 20 同時接続して観察
- まとめ: App Runner のオートスケールは Cloud Run ほど滑らかではなさそう
- 補足: App Runner の裏側は Fargate タスク (2023/05/06 追記)
先日、 AWS から App Runner というサービスが発表された。すごく GCP の Cloud Run っぽい。
ただ、新規サービス作成に 5 分待たされてしまった。
東京リージョンで nginx サービス作成時間 3 回はかってみたけど
— たいぷらいた〜 (@no_clock) 2021年5月19日
- GCP Cloud Run: 25 秒、 12 秒、 8 秒
- AWS App Runner: 360 秒、 322 秒、 225 秒
だった。内部の作りが全然違うのかなという印象
これはスケーラビリティにも不安があるな… と思い、ざっくりオートスケールの様子を調べた。
方法
コンテナの必要数が、クライアントの同時接続数に比例して増えていくだろうという算段である。コードは Gist に掲載している。
GCP Cloud Run と AWS App Runner のスケーリングの様子をみる · GitHub
サービスの設定は以下の通り。
| 項目 | AWS App Runner | GCP Cloud Run |
|---|---|---|
| リージョン | ECR: ap-northeast-1 App Runner: ap-northeast-1 (アジアパシフィック (東京)) |
GCR: asia (アジア) Cloud Run: asia-northeast1 (東京) |
| vCPU | 1 | 1 |
| メモリ | 2 GB | 256 MiB *1 |
| 同時実行数 | 1 | 1 |
| 最大インスタンス数 | 25 | 25 |
| 最小インスタンス数 | 1 *2 | 0 |
同時接続数 4 で観察
同時接続数を 1 分毎に 1 ずつ増やし、 4 まで増やして観察した。
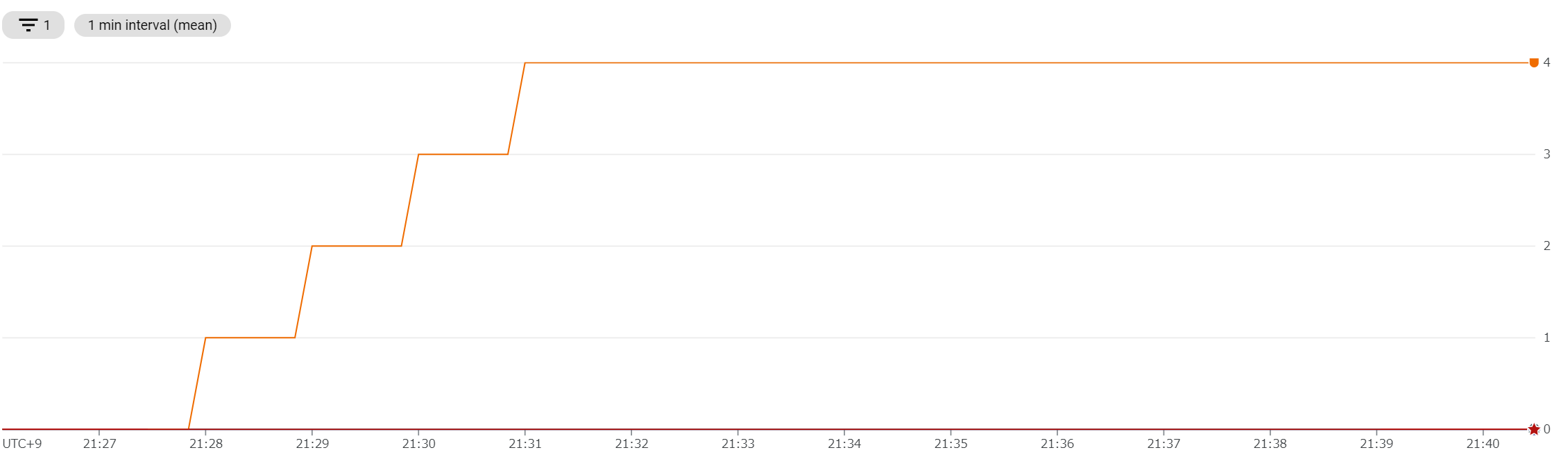
AWS App Runner: 20 インスタンスも起動する


同時接続数 4 のため、計算上は 4 インスタンスあれば十分。しかし、実際は 20 インスタンス起動している瞬間もある。
リクエスト数にきっちり追従していくというより、 余力を多めに確保しながらゆるやかに追従 しているように見える。
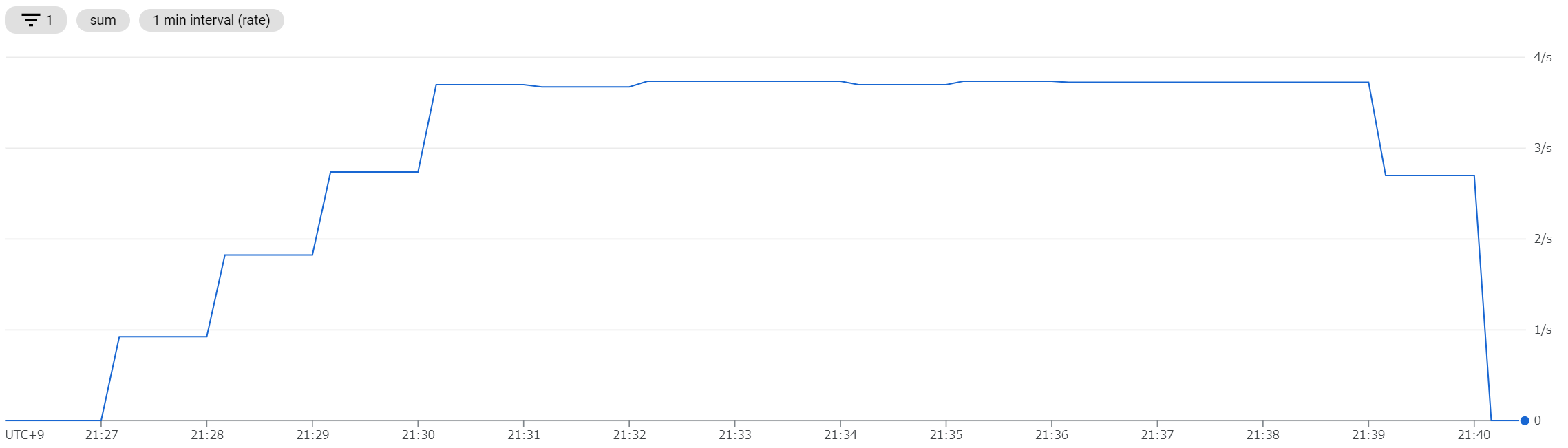
GCP Cloud Run: 4 インスタンスだけ起動する
上が リクエスト/秒 、下がインスタンス数である。こちらはリクエスト数にきっちり追従しているように見える。
突然 20 同時接続して観察
先ほどの結果から、 突然大量のリクエストを投げたら、 App Runner では捌けないのでは? という疑問が湧いたので観察。
httperf で一気に 20 接続、合計 1,000 リクエストを試みた。
$ httperf --ssl --server <hostname> --rate 20 --num-conn 20 --num-call 50
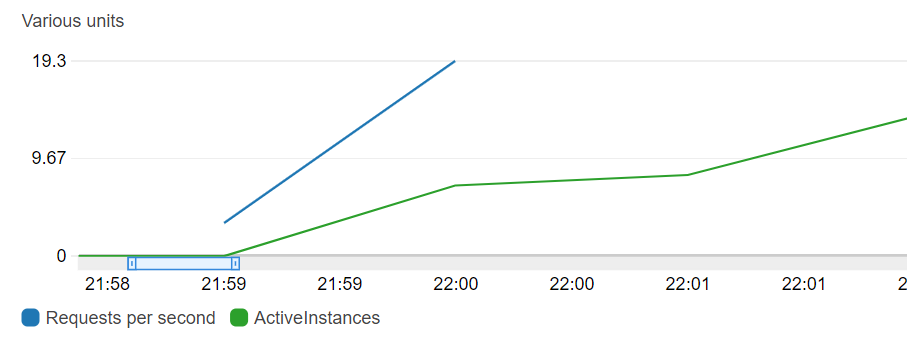
AWS App Runner: 過半数がエラーに
正常なレスポンスはわずか 209 個で 2 割ちょっと。過半数がエラーとなってしまった。
Total: connections 20 requests 762 replies 749 test-duration 28.729 s Connection rate: 0.7 conn/s (1436.4 ms/conn, <=20 concurrent connections) Connection time [ms]: min 552.5 avg 19523.6 max 28361.4 median 21879.5 stddev 6986.8 Connection time [ms]: connect 28.6 Connection length [replies/conn]: 37.450 Request rate: 26.5 req/s (37.7 ms/req) Request size [B]: 95.0 Reply rate [replies/s]: min 7.6 avg 29.7 max 56.0 stddev 17.6 (5 samples) Reply time [ms]: response 503.2 transfer 0.0 Reply size [B]: header 205.0 content 153.0 footer 0.0 (total 358.0) Reply status: 1xx=0 2xx=209 3xx=0 4xx=540 5xx=0 CPU time [s]: user 2.97 system 25.76 (user 10.3% system 89.7% total 100.0%) Net I/O: 11.6 KB/s (0.1*10^6 bps) Errors: total 13 client-timo 0 socket-timo 0 connrefused 0 connreset 13 Errors: fd-unavail 0 addrunavail 0 ftab-full 0 other 0
1 分毎のメトリクスであるが、同時接続数 20 に対し 7 インスタンスほどしか起動できておらず、インスタンスの増加が間に合っていないように見える。
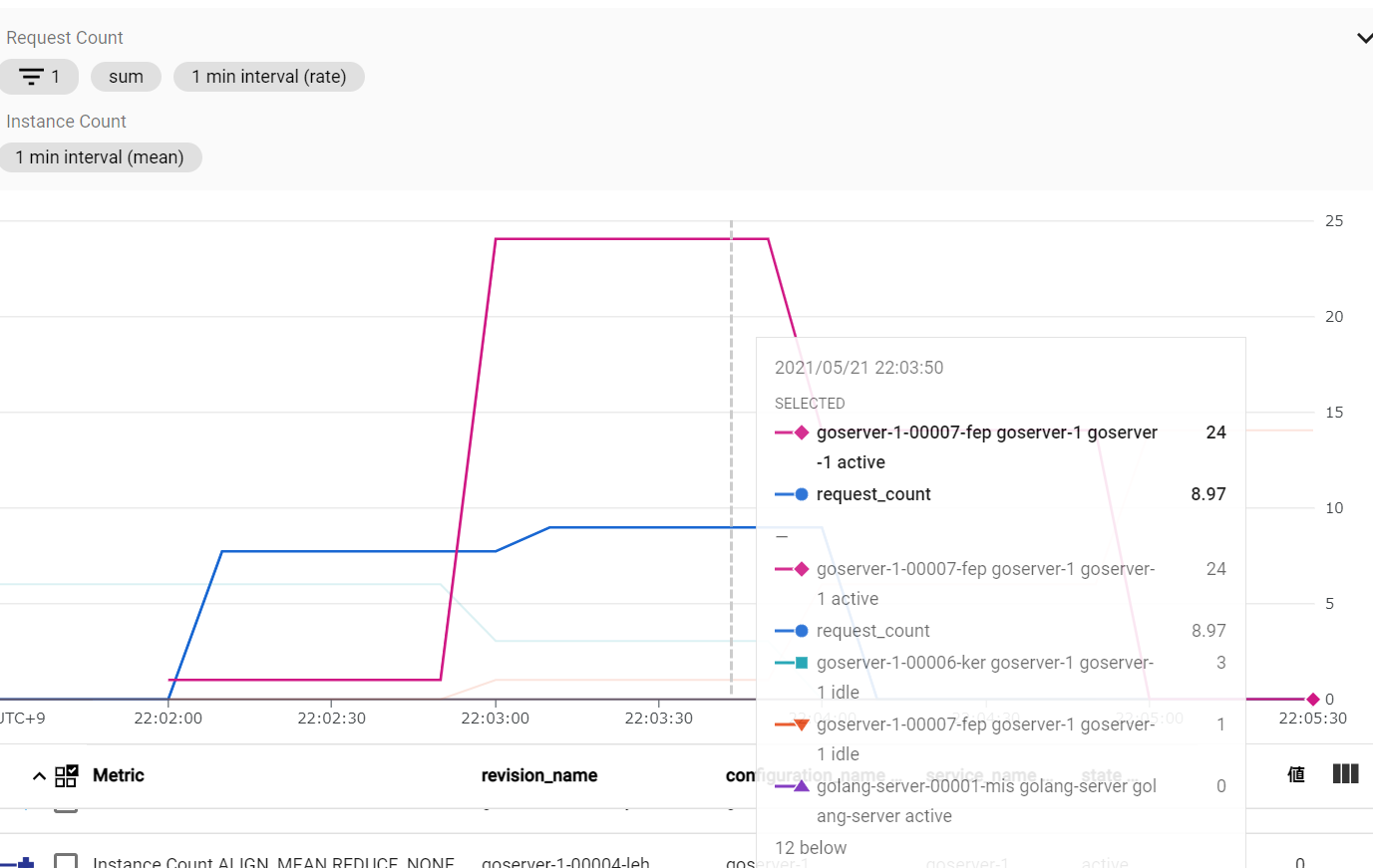
GCP Cloud Run: すべて正常応答
全リクエスト正常にレスポンスを受信した。
Total: connections 20 requests 1000 replies 1000 test-duration 52.689 s Connection rate: 0.4 conn/s (2634.5 ms/conn, <=20 concurrent connections) Connection time [ms]: min 51237.7 avg 51576.9 max 52157.5 median 51512.5 stddev 252.3 Connection time [ms]: connect 48.2 Connection length [replies/conn]: 50.000 Request rate: 19.0 req/s (52.7 ms/req) Request size [B]: 87.0 Reply rate [replies/s]: min 13.6 avg 19.0 max 20.0 stddev 1.9 (10 samples) Reply time [ms]: response 1030.6 transfer 0.0 Reply size [B]: header 378.0 content 278.0 footer 0.0 (total 656.0) Reply status: 1xx=0 2xx=1000 3xx=0 4xx=0 5xx=0 CPU time [s]: user 3.62 system 49.07 (user 6.9% system 93.1% total 100.0%) Net I/O: 13.8 KB/s (0.1*10^6 bps) Errors: total 0 client-timo 0 socket-timo 0 connrefused 0 connreset 0 Errors: fd-unavail 0 addrunavail 0 ftab-full 0 other 0
1 分毎のメトリクスにつき若干不正確だが、瞬時にインスタンス数が増加しているようだ。
まとめ: App Runner のオートスケールは Cloud Run ほど滑らかではなさそう
観察した範囲内では、 App Runner は Cloud Run と比べてオートスケールの動きは緩やか。急激なアクセスの増加に対しては、追従しきれない懸念がありそうな結果だった。
リリースされたばかりのサービスなので、今後に期待。
補足: App Runner の裏側は Fargate タスク (2023/05/06 追記)
AWS App Runner の VPC ネットワーキングに Dive Deep する | Amazon Web Services ブログ より図を引用すると、裏側では Fargate タスクが走っているようだ。

そもそも、 Fargate タスクは Lambda ほど素早く立ち上がらない。以前と比べて随分早くなったが、それでも Lambda や Cloud Run のように数百ミリ秒~数秒ではなく数十秒のオーダーである。あくまで個人的な考えだが、 App Runner に Lambda や Cloud Run 相当のスケーラビリティを求めるのは、そもそも間違っているということなのだろうと思う。
緊急地震速報の配信を支える技術(仮) / テレビとスマートフォン
緊急地震速報の概要(おさらい)

地震波の P 波 と S 波 には速度差があります。この速度差を利用して、揺れの大きな S 波が来る前に予想して知らせるのが緊急地震速報です。
緊急地震速報には 予報 と 警報 の 2 種類があります。テレビやスマートフォン(エリアメール・緊急速報メール)で見聞きするのは 警報 です。警報では、最大震度 5 弱以上が予想される場合に、震度 4 以上が予想される地域などが発表されます。
猶予時間はわずか。迅速な配信が必要
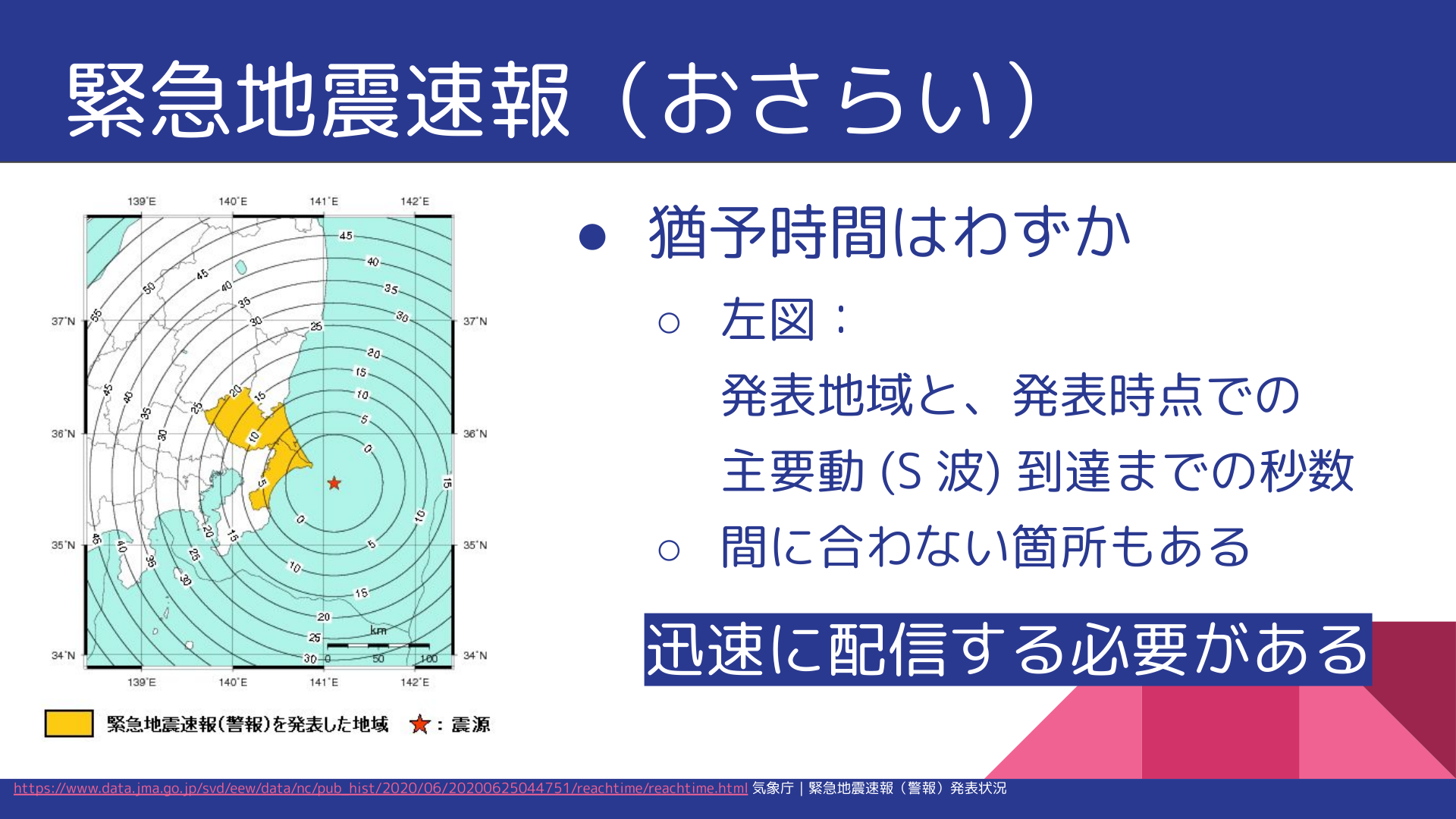
気象庁|緊急地震速報(警報)発表状況 の「主要動到達時間」では、警報発表から主要動 (大きな揺れ) 到達までの時間が図で示されています。
これを見るとわかるように、猶予時間はごくわずかです(間に合わないこともあります)。そのため、緊急地震速報は迅速に配信する必要があります。
テレビ (NHK): 2 種類の音と表示
NHK のデジタルテレビ放送は、 2 種類の音と表示で緊急地震速報を知らせています。
このうち、最初の表示は 文字スーパー 機能を活用していて、素早い配信を実現しています。

「文字スーパー」で低遅延。 2010 年から実施
ピロンピロン… と後から出てくる映像や音声は、デジタル放送の圧縮・伸長処理によって 3~4 秒の遅延があります。一方で、 緊急地震速報 の文字スーパーは 1~2 秒の遅延で済みます。

これを組み合わせることで、まずは文字スーパーですぐに知らせつつ、映像で詳細を伝える、ということが可能になっています。文字スーパーは 2010 年 8 月から利用されています(緊急地震速報 地上デジタル放送での迅速化について)。
なお、 NHK の放送設備については 2-1. 緊急地震速報の放送送出設備の概要 [岡本 隆] に概要があります。ラジオの音声を含めて全自動で送出できるような設備が整えられているようです。
スマートフォン: 2 回の表示
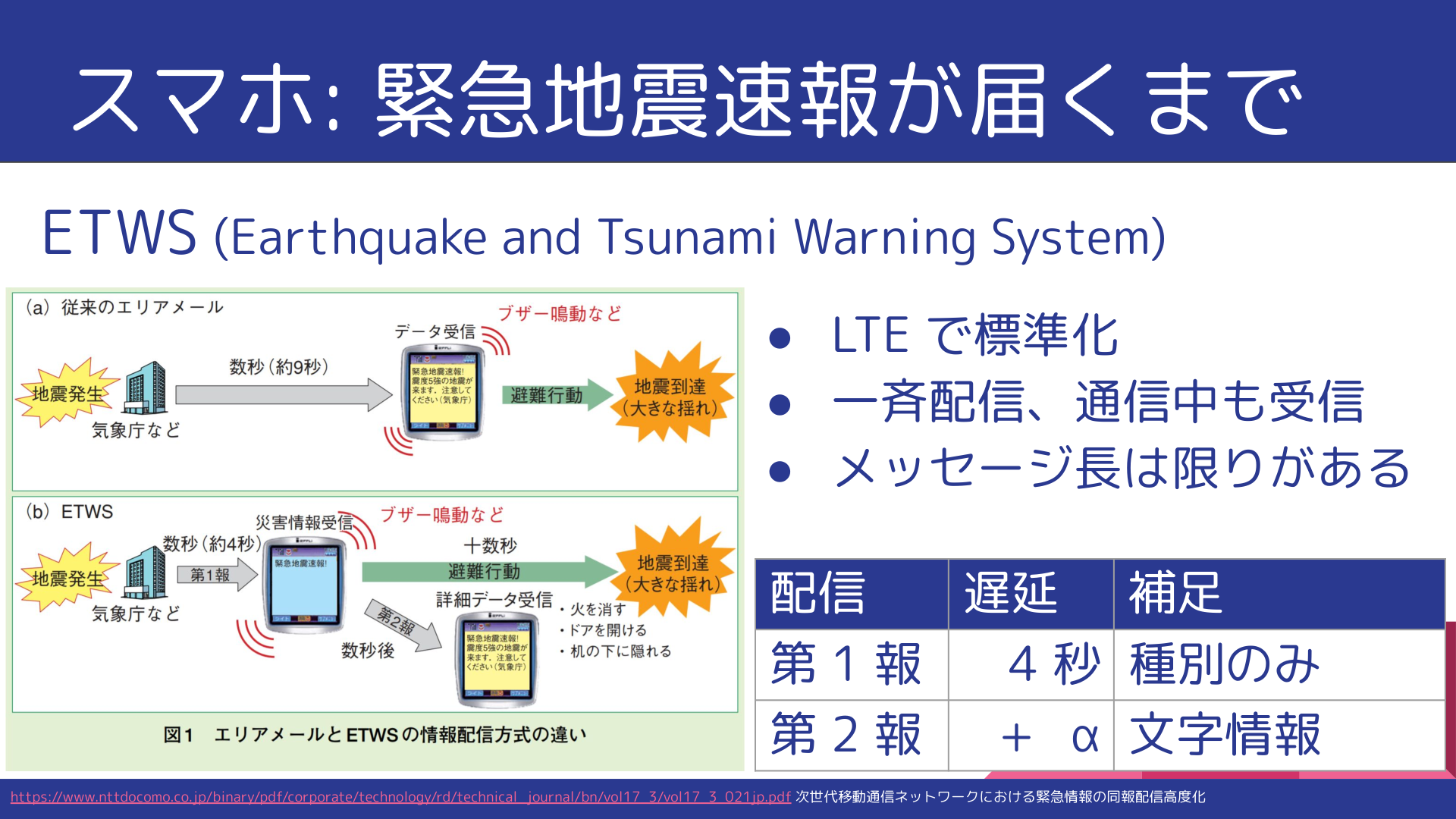
スマートフォンのエリアメール・緊急速報メールは、最初に「強い揺れに備えてください」と表示され、数秒後に「緊急地震速報 XX で地震発生。強い揺れに備えて下さい」と表示が差し替わります(端末により若干異なります)。これは不具合ではなく、迅速に配信するための工夫です。

ETWS で低遅延に
緊急地震速報を含む緊急情報の配信は、 3GPP で ETWS (Earthquake and Tsunami Warning System) として標準化されています。
配信は 第 1 報 (Primary Notification) と 第 2 報 (Secondary Notification) に分かれています。第 1 報は種別のみに絞って短時間で配信し、第 2 報は続報としてメッセージを配信します。途中で表示が差し替わるのは、この第 1 報・第 2 報の受信によるものなのです。
まとめ
- テレビ・スマートフォンとも、配信を 2 段階にわけることで迅速な配信を実現しています。
参考
- 気象庁|緊急地震速報|緊急地震速報のしくみ
- 気象庁|緊急地震速報|緊急地震速報(警報)及び(予報)について
- 気象庁|緊急地震速報(警報)発表状況
- 気象庁|緊急地震速報|緊急地震速報を見聞きしたときは
- 緊急地震速報 地上デジタル放送での迅速化について
- 緊急地震速報の速やかな伝送について検討報告書(詳細)
- 1-2. 緊急地震速報の速やかな伝送手法 [濱住 啓之]
- 標準テレビジョン放送等のうちデジタル放送に関する送信の標準方式
- 標準テレビジョン放送等のうちデジタル放送に関する送信の標準方式別表第十八号注3の規定に基づく地震動警報情報の構成
- 次世代移動通信ネットワークにおける緊急情報の同報配信高度化
もともとライトニングトーク向けにスライドを作成していたのですが、発表する場がないので記事に起こしました。
プロダクションレディ開発プロセス ―SIer の開発標準に学ぶ
新しい Web サービスを「本番環境に載せられる品質で作っていく」のは大変です。一体何から考えればいいのでしょう。インフラ? テーブル? API 仕様?
「MVP (Minimum Viable Product) で」とか「アジャイルで」といった話はよく聞きます。一方で「どのような順番で、何を考えていくと、いい感じに出来上がるのか」という話はあまり聞きません。「Web サービス 作り方」などと調べても、個人開発にフォーカスしたものがほとんど。
これに対する私の解は、「SIer の開発標準に学ぶ」です。
SIer の開発標準
大手 SIer は、開発プロセスを標準化した「開発標準」を持っています。「この通りにやれば誰でも一定品質でシステムが作れる」というガイドラインで、ノウハウの塊でもあります*1。
ありがたいことに、 TIS は CC BY-SA 4.0 で Nablarch 開発標準を公開しています。この Nablarch 開発標準をちょっと覗いてみましょう。
(参考) SIer の開発標準例:
- 富士通: SDEM
- NTT データ: TERASOLUNA の標準手順
- TIS: Fintan の 要件定義フレームワークや Nablarch アプリケーション開発標準 等
- IPA (情報処理推進機構): 共通フレーム 2013 (電子版 500 円、やや抽象的な表現が多いです)
Nablarch の開発標準をちょっと覗く
まずは「開発プロセス標準」にある WBS (Work Breakdown Structure) を見てみましょう。 Excel ファイルですが逃げてはいけません。
「1. 概要」シートには、典型的なウォーターフォールでの開発工程の図があります。

なるほど。では、「要件定義」ではどういったことを考えるのでしょうか。「2. WBS」シートを見てみます。
要件定義: 非機能要件定義
要件定義に「非機能要件定義」なるワークパッケージがあって、補足説明にはこう記されています。
非機能要件定義書には下記のような内容を記載する。
- セキュリティ要件
- バックアップ要件
- 可用性・信頼性要件
- 拡張性要件
- 保守容易性要件
- 性能要件
- システム環境要件
- アプリケーション方式要件
- 外部接続要件
- システム監視要件
- ジョブ運用要件
アーキとインフラが主担当となって作業を進める。
機能だけ実現しても、「ダウンしたことに気づかない(監視要件漏れ)」「ログが出ていなくて調査できない(監視要件漏れ)」「バックアップがなくて戻せない(バックアップ要件漏れ)」なんて事態は望ましくありません。非機能要件定義をすれば、これらを回避できるわけです。
慣れてしまえば「そらそうよ」という内容ですが、意外と忘れたり漏れたりしやすい部分です。
(補足:非機能要件を具体的に決めるには IPA の非機能要求グレードがおすすめです)
外部設計: テーブル定義は INDEX も
要件定義の次は「外部設計」を見てみましょう。「データベース論理設計」ワークパッケージのアウトプットに「テーブル定義書」とあります。
テーブル定義書のサンプルがデータモデル設計にあるので見ましょう。

名称、データ型などのほか、 INDEX の指定まで記入欄があります。
インデックス設計をこの段階で行うかは若干悩ましいですが、少なくとも「インデックス設計は必要な作業である」と認識はできます。
インフラ構築: サイジング設計
今度は、並行する「インフラ構築」の「サイジング設計」ワークパッケージの補足説明を見てみましょう。
機器選定に必要な詳細情報のサイジングを計算する。サイジング設計書には、下記に示す容量について、必要量の見積もりとその根拠を記載する。
- CPU
- メモリ容量
- ディスク容量
ポイントは 根拠を記載する です。インプットに「非機能要件定義書」や「方式設計書」とあり、そこには性能要件やアプリケーションのアーキテクチャなどが記載されています。これらに基づいて計算せよということです。
ただし、 Nablarch 開発標準はおそらく機器購入(オンプレミス)が前提になっています。クラウドサービス前提であれば、実際に動かすなり性能試験するなりして「根拠」が十分揃ってからサイジングするほうが良いでしょう。
めくるめく開発標準の世界
あっさり目ですが、 SIer の開発標準例として Nablarch の開発標準を覗いてみました。
私は既に SIer にはいませんが、それでも次の場面で開発標準(のようなもの)を思い浮かべ、それに助けられていることが多いです。
- 新しいサービス(マイクロサービス含む)を作り始めるとき。大雑把な進め方を決めたり、タスクを洗い出したり、決めるべきことを整理したり、ざっくりと見積もりしたりするとき
- 本番環境へのデプロイ前に、「やるべきことを(やった|やらないという意思決定をした)か」確認するとき
何かのお役に立てれば幸いです。
本記事は Nablarch 開発標準のライセンスを継承し CC BY-SA 4.0 とします*2。
VTuber が歌った曲をまとめたい 後半(実装編)
VTuber が歌った曲をまとめたい 前半(検討編) の続きです。
前半(検討編) のおさらい
- VTuber のすべての動画から、過去どんな曲を歌っていたか列挙したい
- 複数案を検討し、「動画コメント欄の時間指定コメントを使う」案で進むことにした
ざっくりイメージ
「チャンネル URL から曲目データベースができるまで」のざっくりイメージがこちらです。
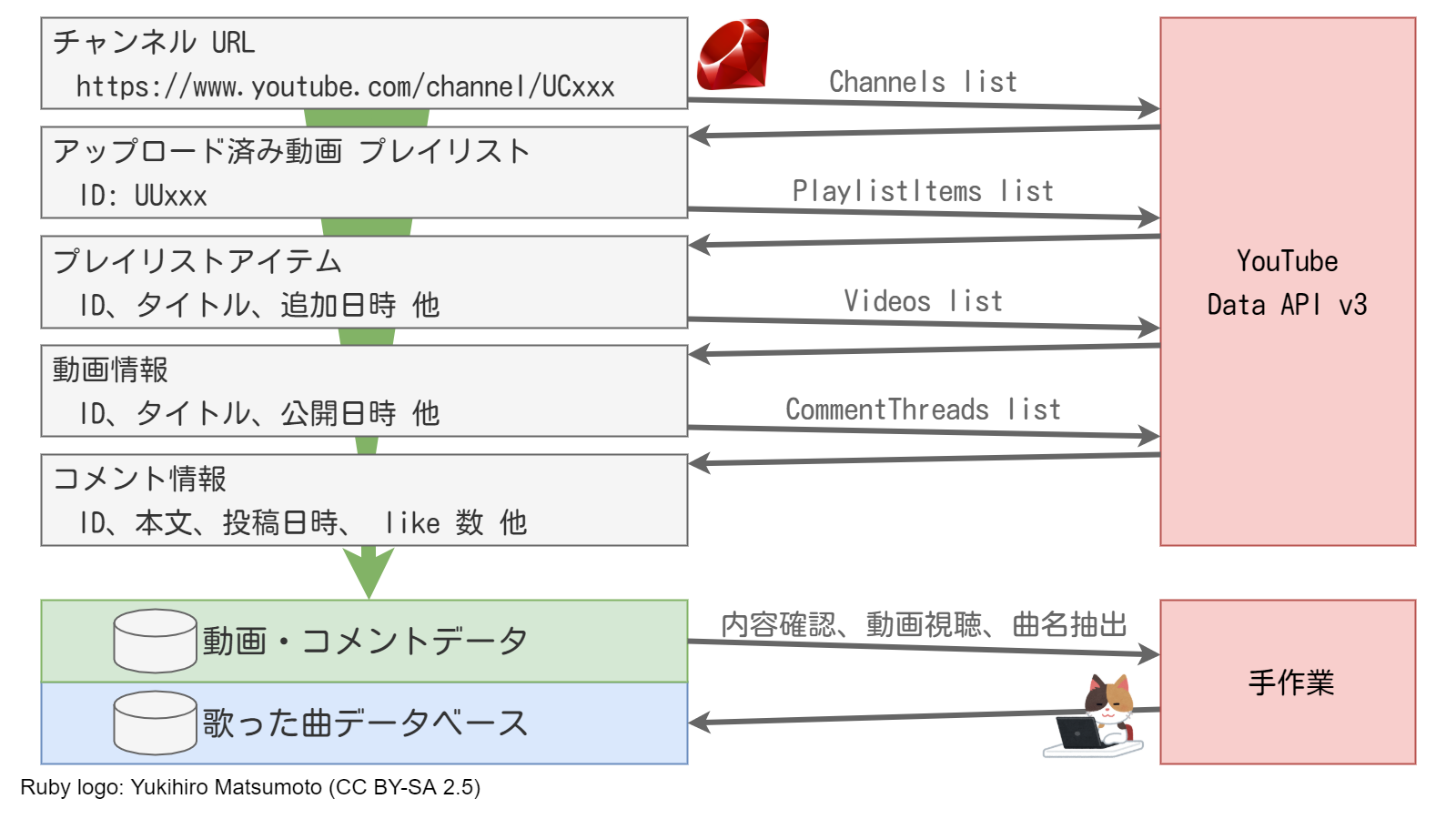
YouTube Data API v3 をフル活用し、 YouTube チャンネルを指定するだけで動画・コメントデータが抽出できるようにします。
ただし、「時間指定コメント」には曲以外のコメントも含まれるため、 データベース化するまでに手作業を挟みます。
データ抽出 (Ruby)
YouTube Data API Reference を参照してゴリゴリ書くだけです。書いたコードは GitHub にあります。
meliuta/utils/youtube-data-api-v3 at main · typewriter/meliuta · GitHub
以下は注意点です。
API クォータ
Quota usage | YouTube Data API Overview | Google Developers
- YouTube Data API は標準で 10,000 queries / day に制限されています。
- 今回使用する API のクォータ消費量はすべて 1 query / request のようです。日本語版ドキュメントにはパーツごとに追加消費がある旨の記述がありますが、英語版にはありません。実際に触ってみても追加消費があるように感じられませんでした。
チャンネル URL → アップロード済み動画 プレイリスト
Channels: list | YouTube Data API | Google Developers
- チャンネル URL の表現方法は 3 種類あります。チャンネル ID (
/channel/UCxxx) 、ユーザ名 (/user/xxx) 、 カスタムチャンネル URL (/c/xxx) です。このうち、カスタムチャンネル URL は非対応ですが、後述する Videos: list API に任意の動画 ID を投げるとチャンネル ID が取得できます。 - 次のステップで用いるプレイリスト ID は、レスポンスに含まれる
contentDetails.relatedPlaylists.uploadsの値を使用します。

アップロード済み動画 プレイリスト → プレイリストアイテム
PlaylistItems: list | YouTube Data API | Google Developers
- 50 を超える動画は 1 回では取得できません。レスポンスの
nextPageTokenがなくなるまで繰り返し取得する必要があります。 - レスポンスに含まれる
snippet.publishedAtはプレイリストへの追加日時であり、動画の公開日時とは異なります。 - 次のステップで用いる動画 ID は、レスポンスに含まれる
contentDetails.videoIdの値を使用します。
プレイリストアイテム → 動画情報
Videos: list | YouTube Data API | Google Developers
- レスポンスのサムネイル (
snippet.thumbnails.(key)) のキーに注意します。日本語版はdefault,medium,highの 3 種類しかありませんが、英語版のドキュメントにはstandard,maxresも記述されており、こちらが正確です。大きい順にmaxres,standard,highmedium,defaultです。
動画情報 → コメント情報
CommentThreads: list | YouTube Data API | Google Developers
- リクエストパラメタの
orderをrelevanceにすると、 YouTube サイト上での「評価順 (Top comments)」と同じ順序になるようです。 - PlaylistItems: list と同様、 100 を超えるコメントは 1 回では取得できません。レスポンスの
nextPageTokenを利用して繰り返し取得します。 - 曲目を列挙したコメントは評価が高いケースも多いため、 API クォータを意識して途中で打ち切るのも手です。
コメント情報 → 時間指定コメントの抽出

- コメントの
snippet.textOriginalを正規表現/(d+:\d+:\d+|\d+:\d+)/に掛けるだけのシンプルな方法で抽出します。 - コメントは自由形式で、曲名が同一行にあったり次行にあったりします。あまり最適化をせず、時間指定コメントをとにかく抽出することに割り切っています。
データベース化(手作業)
抽出したデータからデータベースを作っていきます。これは完全に手作業です。
- 曲名っぽい時間指定コメントを取捨選択
- 動画を再生して確認
- 曲名・アーティストなどを検索・記録
今回は素敵な素敵な「Google スプレッドシート」を使用しました。だいたい 1,800 コメントから 100 曲ほどをデータベース化できました。

なお、動画の時間指定リンクは https://www.youtube.com/watch?v=sshoDk2CQVQ&t=14118 のように、 t=秒数 を指定するだけです。
Web サイト化 (TypeScript, React)
こちらもゴリゴリ書くだけです。書いたコードは GitHub にあります。
API サーバを立てたくなかったため、フロントエンドでがんばる方向にしました。 Web サーバに生成物をポン置きするだけです。
- データベースは tsv ファイル
- TypeScript + React
- tsv ファイルの取得・解析
- material-table を使った表(検索・ページング機能含む)
出来上がった Web サイトがこちらです。
メリうた🐝 - メリッサ・キンレンカさんのお歌非公式まとめサイト
まとめ
なお、開発にあたり レヴィ・エリファ アーカイブス から着想を得ました。この場を借りて御礼申し上げます。